본 문서는 2023년 6월에 작성된 문서입니다. 시간이 지나면 현재 시험 방식과 많이 다를 수 있습니다.
저는 회사에서 2년 넘게 Kubernetes를 사용을 하여 Kubernetes에 익숙한 상태였고 이왕 Kubernetes를 사용할 줄 알게 된 거 이 기회에 CKA를 취득하는 게 좋을 것 같아 시험을 보게 되었습니다. CKA 준비 기간은 2 ~ 3주 정도 걸렸으며 모든 부분을 공부한 것이 아닌 부족한 부분만 골라 보면서 공부를 하였습니다.
결제는 어떻게?
https://training.linuxfoundation.org/certification/certified-kubernetes-administrator-cka/
Certified Kubernetes Administrator (CKA) Exam | Linux Foundation
Training in skills, knowledge, and competency to perform the responsibilities of Kubernetes administrators.
training.linuxfoundation.org
결제 진행 방식은 위 링크를 통해 Linux Foundation에 로그인 후 결제를 진행하면 됩니다. 여기서 약간의 팁은 CKA는 자주 할인을 진행하는데 적게는 15%에서 많게는 40%까지 할인을 받을 수 있습니다. 저 같은 경우 40% 해택을 받아 321,256원으로 결제할 수 있었습니다. 여기서 환율이 적용되기 때문에 환율이 좋을 때 구매를 진행하시면 같은 40% 할인이어도 실제 구매한 가격이 다를 수 있습니다.
할인 코드 확인 방법은 https://training.linuxfoundation.org/blog/ Linux Foudation 블로그에 게시물로 업로드가 되는데 그때 코드를 받아 결제를 진행하시면 됩니다.

CKA 공부 방법
저는 회사에서 Kubernetes를 2년 이상 사용하였습니다. 회사에서 사용하였을 때는 "마사야 야오야마"가 지은 "쿠버네티스 완벽 가이드"라는 책으로 공부를 하였고 CKA 준비를 하기 위해서는 Udemy에 "Mumshad Mannambeth"의 "Certified Kubernetes Administrator (CKA) with Practice Tests" 강의를 들었습니다. 저는 어느 정도 Kubernetes를 사용하여 부족한 부분만 골라서 강의를 들었습니다. 여기서 제공하는 실습문제가 실제로 많이 도움이 되었기 때문에 실습문제는 반드시 풀어보는 게 좋습니다. 이 강의 또한 할인을 자주 하기 때문에 관심등록을 통해 할인한다는 알림을 받게 되면 그때 구입하는 것을 추천드립니다. 원래 가격은 99,000원이지만 할인을 받게 되면 15,000에서 20,000원에 결제할 수 있습니다.
https://www.udemy.com/course/certified-kubernetes-administrator-with-practice-tests/
Killer.sh 후기
CKA 시험을 결제하게 되면 Killer.sh라는 실제 시험 환경과 아주 비슷한 환경을 제공해 줍니다. 세션을 시작하면 36시간 동안 지속적으로 비슷한 시험 환경에서 예상문제를 풀 수 있는 세션을 2개 줍니다. 1개의 세션은 36시간 동안 접속할 수 있기 때문에 주말에 문제를 여러 번 풀어보면 많은 도움이 됩니다. 세션은 2개 주지만 2개의 세션 모두 시험문제가 동일하니 굳이 2개의 세션을 사용하지 않으셔도 됩니다. 참고로 Killer.sh는 실제 CKA 시험 문제보다 어려운 문제가 나오니 여기서 좋지 못한 점수를 받았다고 낙심하지 마세요. 그리고 Killer.sh는 문제와 풀이 과정까지 전부 PDF로 제공하여 부족한 부분을 공부하는데 좋습니다.
CKA 당일!!!
PSI 브라우저 설치
시험 날짜를 정하고 나면 이메일로 PSI 브라우저를 설치할 수 있는 링크를 보내줍니다. PSI 브라우저는 시험 보기 30분 전에 설치할 수 있으며 설치가 완료되고 PSI를 구동하면 PSI와 동시에 동작할 수 없는 프로세서를 강제적으로 종료하고 시험에 입장을 하게 됩니다. 이때 PSI와 같이 동작할 수 없는 프로그램은 대표적으로 크롬입니다. 참고로 PSI에서 버튼을 누르면 PSI가 알아서 프로그램을 종료하니 미리 프로그램을 종료하지 않으셔도 됩니다.
준비물
폐쇄된 공간(집보다는 주말에 회사에 출근하여 폐쇄된 회의실에서 시험을 보는 것을 추천), 여권, 웹캠(노트북 가능), 최소 15인치 이상의 화면(듀얼모니터 불가능)
감독관과의 소통
PSI 브라우저 설치가 모두 정상적으로 끝나면 감독관과 채팅을 하게 되는데.. 영어를 잘 모르는 저의 입장에서는 모든 시험 통틀어서 가장 힘든 순간이었습니다. 먼저 여권으로 신원을 확인하고 노트북에 달린 웹캠으로 시험 보는 공간을 감독관에게 확인시켜주어야 합니다. 그리고 감독관이 주변에 어떠한 물건을 치우라고 하면 바로바로 치워주면 시험을 시작하게 됩니다. 저는 감독관과 채팅을 시작하자마자 "I am not good english"라고 알려주었더니 제가 영어를 못 알아듣는 거 같으니 감독관 단어 하나씩 채팅에 쳐서 알려주는 친절함을 보여주었습니다. 그러니 영어를 잘 모르더라도 너무 두려워하지 않으셔도 됩니다.
실제 시험 환경
시험장에 들어가면 아래 이미지와 같은 환경에서 시험을 보게 됩니다. 우측 상단에는 응시자(본인)의 얼굴이 나오는데 화면에 반드시 얼굴이 벗어나면 안 됩니다. 얼굴이 화면에 벗어나게 되면 채팅창으로 감독관이 카메라에 얼굴이 나와야 된다는 메시지를 보냅니다. 그리고 가장 중요한 팁은 바로 복사 붙여 넣기인데요 저는 윈도우 노트북으로 시험을 진행하였는데 터미널과 파이어폭스, 메모장의 복붙 단축키가 다릅니다.
터미널 : ctrl + shift + c(복사), ctrl + shift + v(붙여 넣기)
파이어폭스, 메모장 : ctrl + c(복사), ctrl + v(붙여 넣기)
파이어폭스 Kubernets document에서 yaml을 복사할 때는 ctrl + c로 복사하여 터미널에서는 ctrl + shift + v로 붙여 넣어야 합니다.
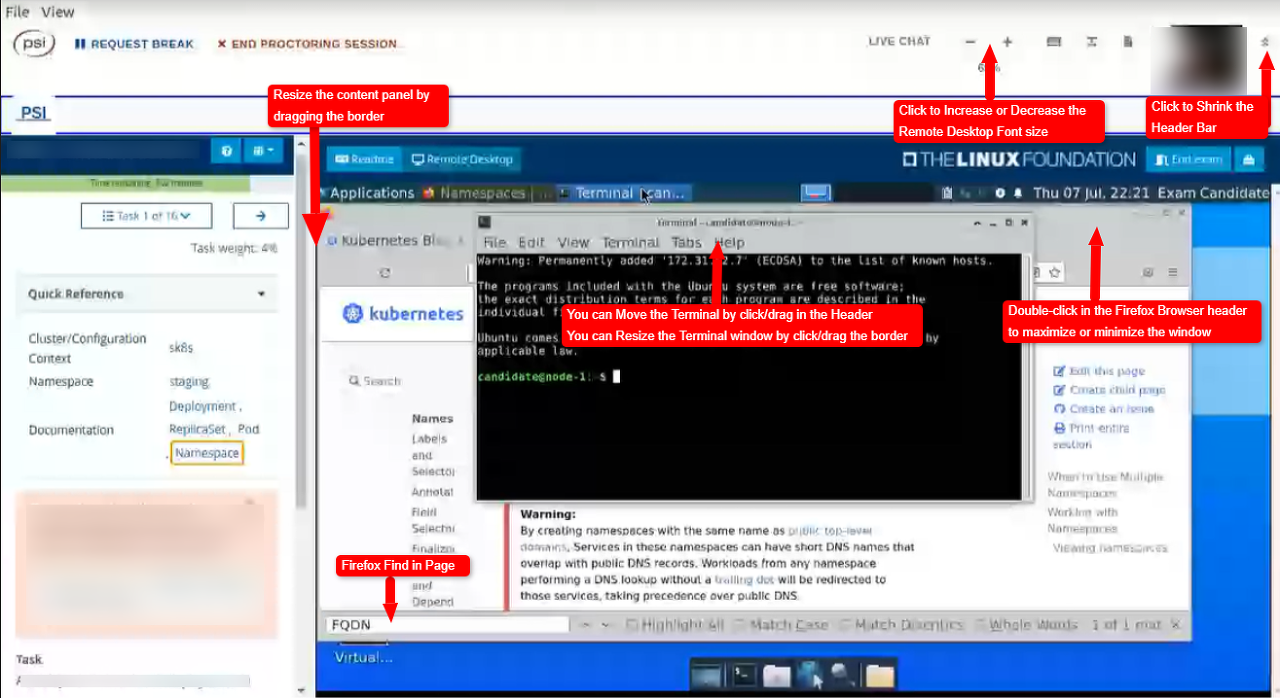
참고로 현재는 문제의 언어를 선택할 수 있는데 영어, 중국어, 일본어만 제공하고 있습니다.
그리고 정말 인터넷이 아주 느리니 무조건 유선으로 시험 보는 것을 추천드리고 생각보다 PSI 브라우저가 매우 무겁습니다. 그렇기 때문에 어느 정도 성능이 좋은 컴퓨터로 시험을 보는 것을 추천드립니다.
CKA 문제 유형
문제는 15 ~ 20개 정도 나오고 2시간 동안 풀 수 있습니다. 저의 경우 17문제 나왔고 문제의 유형은 아래 리스트처럼 나왔습니다.
- pod 생성
- 멀티 컨테이너 pod 생성
- 사이드카 컨테이너 pod 생성
- deploy, statefulset, daemonset 등 생성
- service expose
- pv, pvc 생성 후 마운트
- ingress, networkpolicy
- rbac
- etcd 백업
- version upgrade
- Troubleshooting
CKA Tip
- kubectl 자동완성은 기본적으로 적용되어 있습니다.
- alias k="kubectl"은 기본적으로 적용되어 있습니다.
- etcdctl 이 이미 설치되어 있습니다.
- export do="--dry-run=client -o yaml"를 미리 정의해 두면 dry-run을 수행할 때 조금은 더 빠르게 작업할 수 있습니다.
- kubectl create --help를 통해 create로 생성할 수 있는 리소스는 create로 생성하고 create로 생성할 수 없는 리소스는 kubernetes document에서 복사하는 게 빠릅니다. (예시로 pv, pvc는 빨리 document에서 복사해 오자)
- PSI 브라우저 바탕화면에서 우클릭하여 메모장을 생성 후 사용할 수 있습니다.
- 파이어폭스에서 ctrl + f로 검색을 하고 아래에 search highlight 체크박스 선택을 통해 검색을 강조하여 볼 수 있습니다.
- 파이어폭스에서 실수로 ctrl + shift + c를 누르면.. 개발자 모드가 나오는데 인터넷이 매우 느려 개발자 모드를 끄는데도 5 ~ 10초 정도 소요됩니다.
- 내 얼굴이 나오는 상단 메뉴를 접어 화면을 조금 더 크게 사용할 수 있다.
외우면 좋은 거
- etcd 백업 방법
- manifest위치 (/etc/kubernetes/manifests)
- PKI 위치 (/etc/kubernetes/pki/)
- 파드 DNS 확인 (kubectl exec -it 파드명 -- cat /etc/resolv.conf)
- kubelet 로그 확인 (journalctl -u kubelet)
CKA 시험 결과
2023년 6월 6일 시험을 봤고 6월 7일에 시험 결과가 나왔고 결과는 한 번에 합격할 수 있었습니다.!!!
CKA에 도전하는 분들 모두 응원합니다.


'Kubernetes' 카테고리의 다른 글
| ArgoCD를 이용한 Kubernetes Application 배포 자동화 (0) | 2025.04.12 |
|---|---|
| Argo Rollouts을 사용한 배포 전략 (0) | 2025.04.08 |
| kubernetes max pods 개수 수정 (0) | 2024.07.31 |
| [Helm] helm package를 ArtifactHub에 등록하기 (with github) (0) | 2023.07.16 |
| [Helm] Helm 기본 명령어 (0) | 2023.07.15 |