
ILM policy로 data phases 설정
data phases를 구성한다는 것은 성능을 올린다기보다는 자원을 효율적으로 사용하는 방법입니다. Elasticsearch 인덱스의 document를 수정하거나 삭제하는 것은 역색인 방식에서는 많은 자원을 소모하게 되기 때문에 데이터를 document 단위로 관리를 하는 것보다는 주로 인덱스 단위로 삭제하여 효율적으로 스토리지 사용량을 유지할 수 있습니다. 그래서 Elasticsearch에서는 ILM(Index Lifecycle Management)를 이용하여 인덱스의 생명주기를 자동으로 관리해 주는 기능을 제공하고 있습니다. 이번 문서에서는 ILM을 이용하여 자원을 효율적으로 관리하는 방법에 대하여 기록하였습니다.
Data phases 수행을 위한 노드 설정
많은 사용자가 로그를 분석하기 위해서 Elasticsearch를 사용합니다. 로그의 데이터를 효율적으로 관리하기 위해 많은 사용자들이 로그 인덱스를 날짜 별로 생성하여 사용하고 당일 로그를 분석하기 위해 해당 인덱스에서 많은 조회를 수행합니다. 그리고 다음날이 되면 어제 생성되었던 인덱스에서는 데이터가 들어가지 않고 오늘 날짜로 된 로그 인덱스가 새롭게 생성되어 오늘 날짜의 인덱스에 데이터가 들어가게 됩니다. 이러한 특징을 이용하여 Data phases 설정을 통하여 각각의 노드에 역할을 부여하고 해당 역할에 어울리는 자원을 할당하여 자원을 효율적으로 사용할 수 있습니다. 이번 실습을 위해 저는 Master 3대, Hot 2대, Warm 2대, Cold 2대를 구성하여 테스트를 진행하였습니다.
Hot node
hot 노드에는 데이터가 현재도 인덱싱 되며 자주 사용되는 데이터를 보관합니다. 데이터를 읽고 쓰는 작업이 빈번하게 이루어지기 때문에 SSD 스토리지를 사용하는 것을 권장합니다.
- roles : data, data_content, data_hot
Warm node
데이터가 거의 인덱싱 되지 않으며, 데이터를 읽는데 주로 사용하는 노드입니다.
- roles : data_warm
Cold node
데이터도 인덱싱 되지 않으며, 데이터를 읽는 쿼리 또한 거의 사용하지 않는 노드입니다. 주로 Searchable snapshot을 cold node를 통하여 사용하지만 Searchable snapshot은 Enterpise license에서 제공하기 때문에 이번 실습에서는 Searchable snapshot을 사용하지 못하였습니다.
- roles : data_cold
ILM Policy 생성
ILM Policy 생성
PUT http://localhost:9200/_ilm/policy/my_log_ilm
Content-Type: application/json
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_age": "1d",
"max_size": "10gb",
"max_docs": 10
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "2m",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"shrink": {
"number_of_shards": 2
},
"allocate": {
"number_of_replicas": 1
},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "4m",
"actions": {
"allocate": {
"number_of_replicas": 0
},
"set_priority": {
"priority": 10
},
"freeze": {}
}
},
"delete": {
"min_age": "6m",
"actions": {
"delete": {}
}
}
}
}
}
Hot tier 설정 파라미터 설명
- min_age: "0ms" 인덱스가 생성되자마자 hot tier로 지정됩니다.
- actions.rollover.max_age: rollover가 발생되는 조건으로 인덱스가 생성되고 하루(1d)가 지나면 인덱스가 rollover 됩니다.
- actions.rollover.max_size: rollover가 발생되는 조건으로 인덱스의 크기가 10gb를 넘어가면 인덱스가 rollover 됩니다.
- actions.rollover.max_docs: rollover가 발생되는 조건으로 인덱스의 document의 개수가 10개 넘어가면 rollover 됩니다. 이 설정은 테스트를 위해 아주 작은 값을 넣었습니다. 실제로는 입력하지 않다도 됩니다.
- actions.set_priority.priority: 노드의 문제가 생길 경우 hot 데이터를 복구하는 것은 우선순위를 가장 높게 설정합니다.
Warm tier 설정 파라미터 설명
- min_age: 인덱스가 rollover된지 2분이 지나면 해당 인덱스는 Warm tier로 설정됩니다.
- actions.forcemerge.max_num_segments: 이 설정은 hot tier에서 여러 루씬 세그먼트를 사용한 것을 하나로 합치는 것을 의미합니다. 더 이상 데이터가 해당 인덱스에 써지지 않을 경우에 이 설정을 넣는 것을 권장합니다.
- actions.shrink.number_of_shards: 여러 샤드로 나누어진 것을 2개로 합칩니다. 샤드의 수가 줄어 마스터 노드의 부하를 줄여줍니다.
- actions.allocate.number_of_replicas: 복제 샤드를 1개로 설정합니다.
- set_priority.priority: 인덱스 복구 우선순위를 hot tier보다 낮게 설정합니다.
Cold tier 설정 파라미터 설명
- min_age: 인덱스가 rollover된지 4분이 지나면 해당 인덱스는 Cold tier로 설정합니다.
- actions.allocate.number_of_replicas: 인덱스의 복제 샤드를 제거하여 디스크 사용량을 줄여줍니다.
- set_priority.priority: 인덱스 복구 우선순위를 Warm tier보다 낮게 설정합니다.
- freeze: 해당 인덱스를 읽기 전용으로 설정합니다.
Delete 설정 파라미터 설명
- min_age: 인덱스가 rollover된지 6분이 지나면 해당 인덱스를 삭제합니다.
ILM Policy 설정을 통하여 데이터의 Tier가 변경되기 위해서는 먼저 Rollover가 발생하여야 합니다. 이번 테스트를 위해 doc의 개수가 10개 이상이면 rollover가 발생하도록 설정을 하였고 warm은 2분 뒤 cold는 4분 뒤 delete는 6분 뒤로 아주 짧게 시간을 설정하였습니다.
Index Tempalte 설정
ILM Policy 설정을 적용한 Index template을 구성합니다. 인덱스 template 설정에 대한 설명은 다음 링크를 통해 확인해 주세요
https://stdhsw.tistory.com/entry/Elasticsearch%EC%9D%98-Index-template-%EC%84%A4%EC%A0%95
PUT http://localhost:9200/_template/my_log_template
Content-Type: application/json
{
"index_patterns": ["my_log-*"],
"settings": {
"index": {
"number_of_shards": "4",
"number_of_replicas": "1",
"refresh_interval": "5s",
"lifecycle": {
"name": "my_log_ilm",
"rollover_alias": "my_log"
}
}
},
"mappings": {
"properties": {
"app": {
"type": "keyword"
},
"level": {
"type": "keyword"
},
"message": {
"type": "text"
}
}
}
}
빠른 테스트를 위한 클러스터 설정(무시해도 됩니다.)
테스트를 진행하는데 너무 오랜 시간을 투자할 수 없기 때문에 Elasticsearch에서 Index를 롤오버를 검사하고 수행하는 주기를 10초로 줄여줍니다. 만약 이 설정을 추가하지 않을 경우 기본값으로 10분의 시간이 소요됩니다. 테스트를 위해 설정을 해주었지만 상용서버에서는 설정을 변경하지 않는 것을 권장드립니다.
PUT http://localhost:9200/_cluster/settings
Content-Type: application/json
{
"persistent": {
"indices.lifecycle.poll_interval": "10s"
}
}
인덱스 생성하기
인덱스를 수동적으로 먼저 생성해 주는 이유는 is_write_index 옵션을 사용하기 위해서입니다.
PUT http://localhost:9200/my_log-000001
Content-Type: application/json
{
"aliases": {
"my_log": {
"is_write_index": true
}
}
}
인덱스에 데이터 넣기
테스트를 위한 데이터를 벌크를 통하여 넣어줍니다. 한번에 rollover가 발생할 수 있도록 10개의 document를 넣습니다.
curl -XPOST http://localhost:9200/my_log/_bulk -H 'Content-Type: application/json' -d '
{ "index": {} }
{ "app": "my-app", "level": "debug", "message": "successes hello world" }
{ "index": {} }
{ "app": "my-app", "level": "info", "message": "hello world" }
{ "index": {} }
{ "app": "my-app", "level": "error", "message": "failed hello world" }
{ "index": {} }
{ "app": "my-app", "level": "warn", "message": "warning hello world" }
{ "index": {} }
{ "app": "my-app", "level": "debug", "message": "successes hello world" }
{ "index": {} }
{ "app": "my-app", "level": "info", "message": "hello world" }
{ "index": {} }
{ "app": "my-app", "level": "error", "message": "failed hello world" }
{ "index": {} }
{ "app": "my-app", "level": "warn", "message": "warning hello world" }
{ "index": {} }
{ "app": "my-app", "level": "error", "message": "failed hello world" }
{ "index": {} }
{ "app": "my-app", "level": "warn", "message": "warning hello world" }
'인덱스 생성 결과
인덱스 생성된 결과를 보면 my_log-000001은 hot node에만 생성된 것을 확인할 수 있습니다.
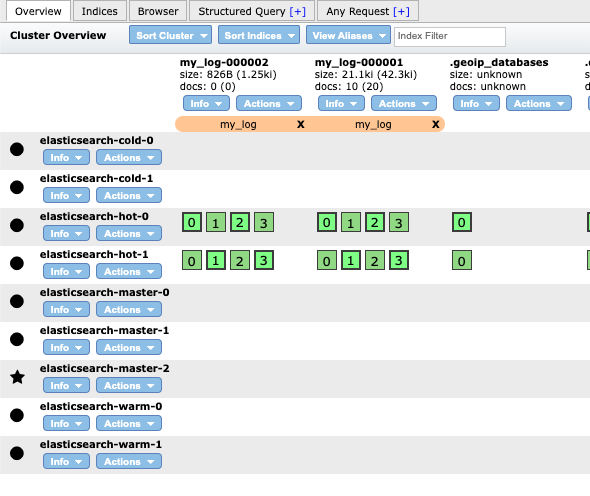
Hot node에서 Warm node로 인덱스 이동
인덱스가 생성되고 롤오버 된 지 2분이 지나면 해당 데이터는 warm노드로 이동합니다. 이때 ILM Policy에서 값을 설정한 것처럼 인덱스의 샤드가 2개로 합쳐지면서 해당 인덱스의 이름 앞에 shrink이라는 단어가 추가되었습니다. 인덱스의 명칭이 변경되었지만 원래의 인덱스 이름으로 alias가 생성되었기 때문에 원래 인덱스 이름 그대로 검색을 하여도 전혀 문제가 발생하지 않습니다.
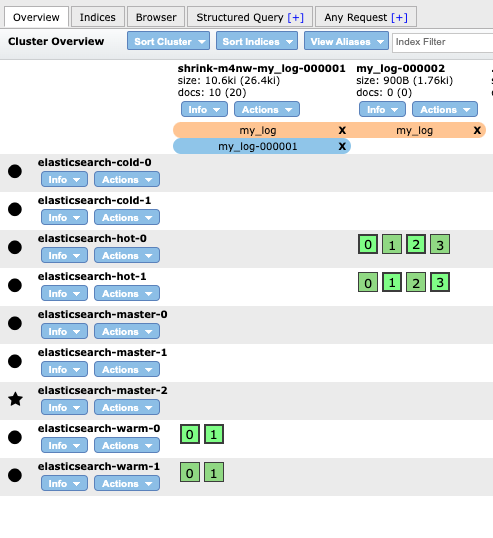
Warm node에서 Cold node로 인덱스 이동
인덱스가 롤오버된지 4분이 지나면 해당 인덱스는 Cold 노드로 이동하게 됩니다. 이것 또한 ILM Policy에 값을 설정한 것처럼 복제 샤드를 제거하였고 해당 인덱스는 읽기 모드로 전환된 상태입니다. 여전히 원래 인덱스 이름으로 alias를 가지고 있기 때문에 원래 인덱스명으로 검색이 가능합니다. 주로 Cold 데이터는 Searchable snapshot을 이용하지만 위에서 언급한 것처럼 Searchable snapshot은 Enterpise license에서만 제공하기 때문에 이번 실습에서는 그냥 warm노드처럼 사용하였습니다.

Cold node에서 인덱스 삭제까지
인덱스가 롤오버 된지 6분이 지나면 해당 인덱스는 삭제됩니다. 아래 이미지를 보면 my_log-000001 인덱스가 삭제된 것을 확인할 수 있습니다.

마지막으로
이번에 빠르게 실습을 하기 위해 data tier의 변경을 아주 짧게 2분 단위로 변경될 수 있도록 하여 테스트를 진행하였습니다. 그러나 실제로는 이렇게 사용하지 않고 일 단위로 tier가 변경되도록 설정을 합니다. 예시로 다음과 같이 설정할 경우 시간 흐름도에 따라 data tier가 변경되는 모습은 다음과 같습니다.
- hot의 min_age: "0ms"
- warm의 min_age: "1d"
- cold의 min_age: "3d"
- delete의 min_age: "7d"

참조
https://www.elastic.co/guide/en/elasticsearch/reference/current/data-tiers.html
Data tiers | Elasticsearch Guide [8.10] | Elastic
Elasticsearch generally expects nodes within a data tier to share the same hardware profile. Variations not following this recommendation should be carefully architected to avoid hot spotting.
www.elastic.co
https://www.elastic.co/guide/en/elasticsearch/reference/current/set-up-a-data-stream.html
Set up a data stream | Elasticsearch Guide [8.10] | Elastic
If you use Fleet or Elastic Agent, skip this tutorial. Fleet and Elastic Agent set up data streams for you. See Fleet’s data streams documentation.
www.elastic.co
https://www.elastic.co/guide/en/elasticsearch/reference/current/ilm-actions.html
Index lifecycle actions | Elasticsearch Guide [8.10] | Elastic
Index lifecycle actionsedit Allocate Move shards to nodes with different performance characteristics and reduce the number of replicas. Delete Permanently remove the index. Force merge Reduce the number of index segments and purge deleted documents. Migrat
www.elastic.co
'Elasticsearch > Elasticsearch 설정' 카테고리의 다른 글
| Elasticsearch version upgrade Swap 방식 (in Kubernetes) (0) | 2023.10.23 |
|---|---|
| Elasticsearch version upgrade rolling 방식 (in Kubernetes) (0) | 2023.10.22 |
| Elasticsearch 최적화 #2] 노드 & JVM (0) | 2023.10.03 |
| Elasticsearch 최적화 #1] 시스템 설정 (0) | 2023.10.03 |
| Elasticsearch reroute 샤드를 다른 노드로 이동시키기 (0) | 2023.10.03 |