보다 더 안정적인 Elasticsearch cluster를 운영하기 위해서는 각각의 데이터 노드가 별도의 서버 Rack에서 동작하도록 설정하는 것을 권장하고 있습니다. 그 이유는 서버의 하드웨어의 이슈가 발생하거나 서버실에서의 화재 또는 네트워크의 문제로 인하여 해당 서버랙이 문제가 발생하게 되면 해당 서버랙에 가동 중인 모든 노드에 영향을 미칠 수 있습니다. 만약 문제가 발생한 서버랙에 여러 대의 데이터 노드가 동작하고 있었다면 치명적인 데이터 유실이 발생하게 됩니다. 그렇기 때문에 각각의 서버랙을 구분하여 인덱스의 Primary shard와 Replica shard를 동일한 서버랙에 배치하지 못하도록 설정을 한다면 서버랙에 문제가 발생하여도 데이터의 유실을 방지할 수 있습니다. 이번 문서에서는 Elasticsearch data node에 rack_id를 부여하여 Primary shard와 Replica shard를 rack_id로 구분하여 배치할 수 있는 방법에 대하여 정리하였습니다.
극단적인 예시로 모든 데이터 노드를 하나의 랙에 동작하고 있다면 해당 랙에 문제가 발생 시 모든 데이터를 유실하여 서비스 운영에 치명적인 문제가 될 수 있습니다. 그렇기 때문에 각각의 서버 랙에 노드를 균등하게 배치하고 각 서버랙이 설치된 데이터 노드에 rack_id를 부여하면 하나의 서버랙에 문제가 발생하여도 데이터는 Replica shard를 통하여 데이터를 보존할 수 있습니다.
데이터 노드 서버 rack_id 설정
"rack one"에 설치되는 데이터 노드의 이름을 elasticsearch-one-0, elasticsearch-one-1, elasticsearch-one-2라고 지정하고 "rack two"에 설치되는 데이터 노드의 이름을 elasticsearch-two-0,elasticsearch-two-1,elasticsearch-two-2라고 설정하도록 하겠습니다.
rack one에 설치 되는 노드 elasticsearch.yml 파일에 값 추가하고 실행하기
node.attr.rack_id: rack_one
rack two에 설치 되는 노드 elasticsearch.yml 파일에 값 추가하고 실행하기
node.attr.rack_id: rack_two
master node에 rack_id를 지정하여 rack_id를 통해 샤드를 할당할 때 replica shard가 primary shard와 rack_id가 같지 않도록 elasticsearch.yml 파일에 다음과 같이 값을 추가합니다.
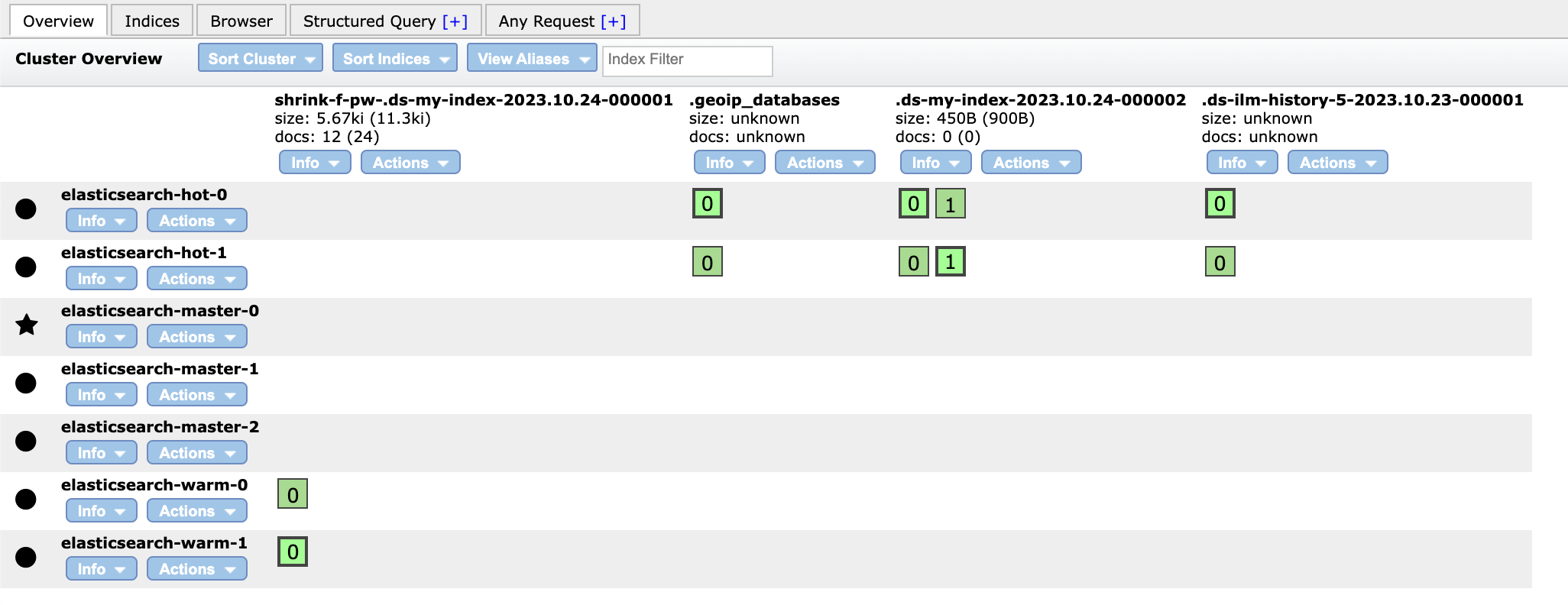
인덱스에 number_of_shards의 값을 4로 설정하고 number_of_replicas의 값을 1로 설정하여 데이터를 인덱싱 하고 테스트를 진행하였습니다.
위 결과로 확인해보면 rack one에 설치된 노드에 primary shard가 생성되면 해당 샤드의 replica shard는 반듯이 rack two에 배치가 된 것을 확인할 수 있습니다. 이렇게 샤드의 배치를 서버랙 기준으로 설정하여 보다 안정적인 서비스를 운영할 수 있습니다.
마지막으로
서버랙을 기준으로 샤드할당을 지정할 수 있지만 zone을 기준으로 샤드할당을 설정할 수도 있습니다. 그러나 AWS Zone을 기준으로 설정할 경우 primary shard와 replica shard가 서로 데이터 sync를 하는 과정에서 너무 많은 네트워크 비용이 발생할 수 있습니다. 회사에서 많은 비용을 투자할 수 있다면 AWS Zone까지 설정하는 것이 가장 최선이지만 저의 경우 네트워크 비용 발생이 부담스러워 비용 발생을 최소화하기 위해 rack_id를 기준으로 샤드를 배치하는 것까지만 설정하고 운영하는 것이 비용 대비 좋은 선택이라고 생각됩니다.
Data Stream은 시계열 데이터를 관리하기 위한 기능으로 하나 이상의 시계열 인덱스를 논리적으로 묶은 그룹으로, 여러 시계열 데이터 소스를 하나의 개체로 인지하여 관리하기 때문에 로그, 이벤트, 지표 및 기타 지속적으로 생성되는 데이터에 적합한 기능입니다. Elasticsearch의 경우 역색인 형태를 가지고 있기 때문에 Document를 삭제하거나 업데이트를 하는데 많이 비율적인 모습을 보이고 있습니다. 그렇기 때문에 데이터를 Document 단위로 관리를 하는 것보다는 인덱스 단위로 관리하는 것이 더 효율적입니다. 이번 문서에서는 시계열 데이터를 data stream을 통해 관리하는 방법에 대하여 정리하였습니다.
Data stream의 인덱싱과 검색 동작 방식
data stream을 통해 데이터를 인덱싱 할 경우 마지막으로 생성된 인덱스에 데이터를 인덱싱을 수행합니다.
그러나 검색은 인덱싱과 다르게 data stream으로 생성된 모든 인덱스에 검색 요청을 수행합니다.
사전 작업(클러스터 구성 및 설정)
먼저 이번 실습을 위해 저는 Master Node 3대, Hot Data 2대, Warm Data 2대로 클러스터를 구성하였으며, 빠른 테스트를 위해 클러스터가 인덱스를 롤오버 검사를 하는 주기를 5초로 설정하였습니다. 설정 방법은 아래와 같습니다.
### 인덱스 롤오버 체크 주기 변경
PUT http://localhost:9200/_cluster/settings
Content-Type: application/json
{
"persistent": {
"indices.lifecycle.poll_interval": "5s"
}
}
ILM(Index Lifecycle Management) 설정
data stream은 ILM(Index Lifecycle Management)를 고려하여 추가된 기능으로 data stream을 사용할 때 ILM 기능과 같이 사용하는 것을 권장합니다. ILM 설정으로는 빠른 테스트를 위해 인덱스가 롤오버 되면 2분 뒤에 Warm 노드로 이동하고 10분 뒤에 Delete 되도록 설정하였습니다. 실제로는 이렇게 짧은 시간으로 설정하지는 않고 최고 일단위로 설정합니다.
데이터가 Warm노드로 이동할 때 shrink 옵션을 통하여 샤드의 개수가 1개로 설정되도록 하였습니다.
Component template 생성
component template은 template의 기능을 여러개로 분리하여 관리하는 기능으로 한번 정의해 놓으면 다른 인덱스 template에서도 재사용할 수 있게 하는 기능입니다. 이번 실습에서는 settings에 관련된 template과 mapping에 관련된 template을 분리하여 생성하였습니다.
데이터 스트림에 인덱싱된 모든 문서에는 또는 필드 유형 @timestamp으로 매핑된 필드가 포함되어야 합니다. 인덱스 템플릿이 필드에 대한 매핑을 지정하지 않으면 Elasticsearch는 기본 옵션을 사용하여 필드로 매핑합니다
> kubectl scale sts elasticsearch-master --replicas=2
# 위 작업 완료 시
> kubectl scale sts elasticsearch-master --replicas=1
# 위 작업 완료 시
> kubectl scale sts elasticsearch-master --replicas=0
# 위 작업 완료 시
> kubectl scale sts elasticsearch-data --replicas=3
# 위 작업 완료 시
> kubectl scale sts elasticsearch-data --replicas=2
# 위 작업 완료 시
> kubectl scale sts elasticsearch-data --replicas=1
# 위 작업 완료 시
> kubectl scale sts elasticsearch-data --replicas=0
# 모든 스케일이 정상적으로 내려가면 기존 자원 반납
> helm delete elasticsearch-master
> helm delete elasticsearch-data
Elasticsearch를 운영하다 보면 처음에 생각하지 못하거나 점점 Elasticsearch에 대한 지식이 늘면서 운영하는 Elasticsearch의 설정을 변경하고 싶은 순간이 있습니다. 뿐만 아니라 보안적인 이슈로 인하여 해당 이슈가 해결된 Version으로 업그레이드를 해야 하는 순간도 겪을 수 있습니다. Elasticsearch의 버전 및 설정을 바꾸는 방법이 여러 가지 있지만 이번 문서에서는 그중에 rolling 방식으로 변경하는 방법에 대해서 정리하였습니다.
주의사항
이번 실습 환경은 Kubernetes 환경에서 실습을 진행하였습니다.
Shard의 Replication이 존재하지 않으면 데이터가 손실될 수 있습니다.
Replication partition의 개수보다 작은 수의 노드가 한 번에 rolling update 되어야 한다는 것입니다. (이해하기 어려우면 그냥 노드 하나씩 업그레이드가 진행되면 됩니다.)
Kubernetes에서는 기본적으로 파드 순서의 역순으로 파드가 업데이트를 진행합니다. 그렇기 때문에 한 번에 드랍되는 문제는 크게 걱정하지 않아도 되지만 억지로 파드를 드랍하는 행위는 해서는 안됩니다.
마스터 노드 또한 업그레이드를 진행해야 되기 때문에 마스터 Role을 가진 노드의 개수가 2대 이상 유지되어야 합니다.
data phases를 구성한다는 것은 성능을 올린다기보다는 자원을 효율적으로 사용하는 방법입니다. Elasticsearch 인덱스의 document를 수정하거나 삭제하는 것은 역색인 방식에서는 많은 자원을 소모하게 되기 때문에 데이터를 document 단위로 관리를 하는 것보다는 주로 인덱스 단위로 삭제하여 효율적으로 스토리지 사용량을 유지할 수 있습니다. 그래서 Elasticsearch에서는 ILM(Index Lifecycle Management)를 이용하여 인덱스의 생명주기를 자동으로 관리해 주는 기능을 제공하고 있습니다. 이번 문서에서는 ILM을 이용하여 자원을 효율적으로 관리하는 방법에 대하여 기록하였습니다.
Data phases 수행을 위한 노드 설정
많은 사용자가 로그를 분석하기 위해서 Elasticsearch를 사용합니다. 로그의 데이터를 효율적으로 관리하기 위해 많은 사용자들이 로그 인덱스를 날짜 별로 생성하여 사용하고 당일 로그를 분석하기 위해 해당 인덱스에서 많은 조회를 수행합니다. 그리고 다음날이 되면 어제 생성되었던 인덱스에서는 데이터가 들어가지 않고 오늘 날짜로 된 로그 인덱스가 새롭게 생성되어 오늘 날짜의 인덱스에 데이터가 들어가게 됩니다. 이러한 특징을 이용하여 Data phases 설정을 통하여 각각의 노드에 역할을 부여하고 해당 역할에 어울리는 자원을 할당하여 자원을 효율적으로 사용할 수 있습니다. 이번 실습을 위해 저는 Master 3대, Hot 2대, Warm 2대, Cold 2대를 구성하여 테스트를 진행하였습니다.
Hot node
hot 노드에는 데이터가 현재도 인덱싱 되며 자주 사용되는 데이터를 보관합니다. 데이터를 읽고 쓰는 작업이 빈번하게 이루어지기 때문에 SSD 스토리지를 사용하는 것을 권장합니다.
- roles : data, data_content, data_hot
Warm node
데이터가 거의 인덱싱 되지 않으며, 데이터를 읽는데 주로 사용하는 노드입니다.
- roles : data_warm
Cold node
데이터도 인덱싱 되지 않으며, 데이터를 읽는 쿼리 또한 거의 사용하지 않는 노드입니다. 주로 Searchable snapshot을 cold node를 통하여 사용하지만 Searchable snapshot은 Enterpise license에서 제공하기 때문에 이번 실습에서는 Searchable snapshot을 사용하지 못하였습니다.
set_priority.priority: 인덱스 복구 우선순위를 hot tier보다 낮게 설정합니다.
Cold tier 설정 파라미터 설명
min_age: 인덱스가 rollover된지 4분이 지나면 해당 인덱스는 Cold tier로 설정합니다.
actions.allocate.number_of_replicas: 인덱스의 복제 샤드를 제거하여 디스크 사용량을 줄여줍니다.
set_priority.priority: 인덱스 복구 우선순위를 Warm tier보다 낮게 설정합니다.
freeze: 해당 인덱스를 읽기 전용으로 설정합니다.
Delete 설정 파라미터 설명
min_age: 인덱스가 rollover된지 6분이 지나면 해당 인덱스를 삭제합니다.
ILM Policy 설정을 통하여 데이터의 Tier가 변경되기 위해서는 먼저 Rollover가 발생하여야 합니다. 이번 테스트를 위해 doc의 개수가 10개 이상이면 rollover가 발생하도록 설정을 하였고 warm은 2분 뒤 cold는 4분 뒤 delete는 6분 뒤로 아주 짧게 시간을 설정하였습니다.
Index Tempalte 설정
ILM Policy 설정을 적용한 Index template을 구성합니다. 인덱스 template 설정에 대한 설명은 다음 링크를 통해 확인해 주세요
테스트를 진행하는데 너무 오랜 시간을 투자할 수 없기 때문에 Elasticsearch에서 Index를 롤오버를 검사하고 수행하는 주기를 10초로 줄여줍니다. 만약 이 설정을 추가하지 않을 경우 기본값으로 10분의 시간이 소요됩니다. 테스트를 위해 설정을 해주었지만 상용서버에서는 설정을 변경하지 않는 것을 권장드립니다.
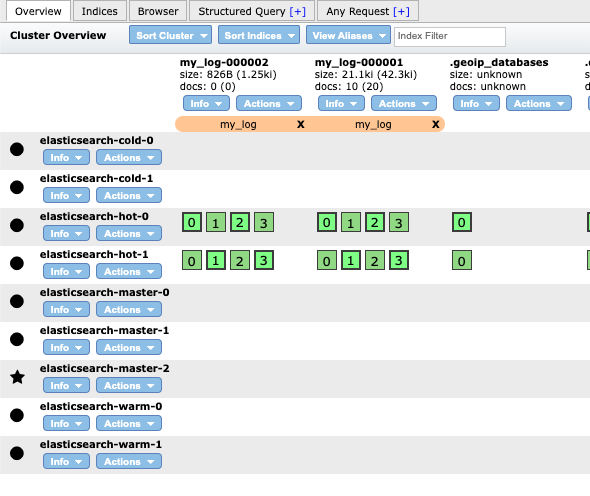
인덱스 생성된 결과를 보면 my_log-000001은 hot node에만 생성된 것을 확인할 수 있습니다.
Hot node에서 Warm node로 인덱스 이동
인덱스가 생성되고 롤오버 된 지 2분이 지나면 해당 데이터는 warm노드로 이동합니다. 이때 ILM Policy에서 값을 설정한 것처럼 인덱스의 샤드가 2개로 합쳐지면서 해당 인덱스의 이름 앞에 shrink이라는 단어가 추가되었습니다. 인덱스의 명칭이 변경되었지만 원래의 인덱스 이름으로 alias가 생성되었기 때문에 원래 인덱스 이름 그대로 검색을 하여도 전혀 문제가 발생하지 않습니다.
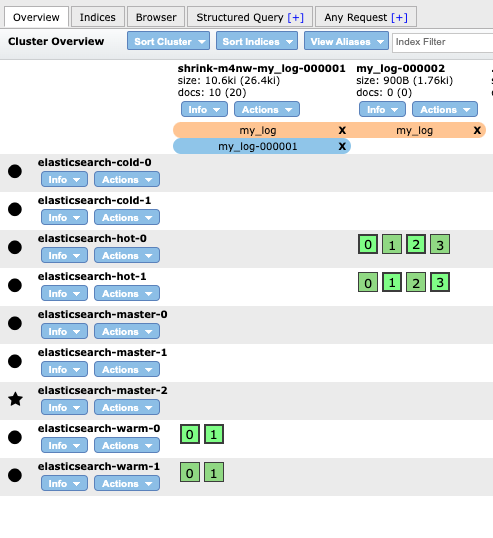
Warm node에서 Cold node로 인덱스 이동
인덱스가 롤오버된지 4분이 지나면 해당 인덱스는 Cold 노드로 이동하게 됩니다. 이것 또한 ILM Policy에 값을 설정한 것처럼 복제 샤드를 제거하였고 해당 인덱스는 읽기 모드로 전환된 상태입니다. 여전히 원래 인덱스 이름으로 alias를 가지고 있기 때문에 원래 인덱스명으로 검색이 가능합니다. 주로 Cold 데이터는 Searchable snapshot을 이용하지만 위에서 언급한 것처럼 Searchable snapshot은 Enterpise license에서만 제공하기 때문에 이번 실습에서는 그냥 warm노드처럼 사용하였습니다.
Cold node에서 인덱스 삭제까지
인덱스가 롤오버 된지 6분이 지나면 해당 인덱스는 삭제됩니다. 아래 이미지를 보면 my_log-000001 인덱스가 삭제된 것을 확인할 수 있습니다.
마지막으로
이번에 빠르게 실습을 하기 위해 data tier의 변경을 아주 짧게 2분 단위로 변경될 수 있도록 하여 테스트를 진행하였습니다. 그러나 실제로는 이렇게 사용하지 않고 일 단위로 tier가 변경되도록 설정을 합니다. 예시로 다음과 같이 설정할 경우 시간 흐름도에 따라 data tier가 변경되는 모습은 다음과 같습니다.
elasticsearch JVM이라고 검색을 해보면 많은 글들이 JVM은 전체 메모리에 50%로 설정하라고 설명하는 곳이 많습니다. 그렇지만 단순히 50%라고만 하기에는 사용자의 환경이 다르기 때문에 설명이 부족합니다. elasticsearch 공식 문서에 따르면 전체 메모리의 50% 이하로 설정하는 것을 권장하고 있으며, 환경에 따라 다르지만 대중적으로 26GB 이하로 설정해야 된다고 설명을 하고 있지만 사용자의 환경에 따라 30GB까지도 설정을 할 수 있다고 합니다. 그 이유는 Zero base comporessed OOP 때문인데요 Compressed OOP는 아래에서 다루도록 하겠습니다. 그리고 JVM 설정에 유의해야 되는 것은 전체 메모리의 50% 이하를 JVM에 줬다면 나머지 메모리는 시스템과 Lucene이 사용하게 됩니다. 그렇기 때문에 통계 및 분석이 많은 쿼리를 자주 사용한다면 JVM에 메모리를 높게 주고(50%에 가깝게) 검색만 주로 하는 쿼리를 자주 사용한다면 JVM메모리를 보다 적게 주어 Lucene이 더 많은 메모리를 사용할 수 있게 하는 것이 좋습니다.
Compressed OOP
포인터의 공간 낭비를 줄이고 좀 더 빠른 연산을 위해 포인터를 압축해서 표현하는 메모리 최적화 기법 중 하나입니다. 이 기법의 원리는 포인터가 메모리 주소를 가리키는게 아닌 Object Offset을 가리키도록 변형해서 동작시키는 것입니다. 만약 8비트 포인터를 사용한다면 256바이트의 물리적인 주소를 표현하는게 아니라 256개의 객체를 가리킬 수 있게 되는 것입니다. 만약 JVM의 크기가 32GB를 넘어가게 된다면 포인터 구조가 Compressed OOP가 아닌 일반 OOP 방식으로 전환되어 Compressed OOP의 이점을 살릴 수가 없습니다. 그러므로 메모리의 여유가 있다면 차라리 노드를 더 늘려 주는 것이 더 현명한 선택이 될 것 같습니다.
Compressed OOP 메모리 주소
32비트 OOP : 2의 32승 까지의 주소를 가리킬 수 있다. 4GB
64비트 OOP : 2의 64승 까지의 주소를 가리킬 수 있다. 18EB
32비트 Compressed OOP : 2의 32승 오브젝트를 가리킬 수 있습니다.
메모리 공간으로는 2의 32승 곱하기 8만큼 표현이 가능합니다.
Zero base Compressed OOP 확인
Zero base Compressed OOP는 JVM의 힙 메모리가 0번지부터 시작하게 하는 설정이다. JVM의 크기가 32GB로 설정하여 Zero base Compressed OOP가 깨진 것과 30GB 이하로 설정하여 Zero base Compressed OOP가 활성화된 것의 차이를 확인해 보겠습니다.
Elasticsearch 공식 문서에 따르면 Xms, Xmx의 값은 동일해야 하며 전체 메모리의 50% 이하로 설정하며 root jvm.options 파일을 수정하지 않는 것을 권장합니다. 저는 Xms, Xmx만 수정하고 나머지는 그냥 이런 것들이 있다는 것만 알고 넘어갔습니다.
-Xms : 기본 heep 사이즈 (기본값 : 64MB)
-Xmx : 최대 heep 사이즈 (기본값 : 256MB)
-XX:PermSize : 기본 Perm 사이즈
-XX:MaxPermSize : 최대 Perm 사이즈
-XX:NewSize : 최소 New 영역 사이즈
-XX:MaxNewSize : 최대 New 영역 사이즈
-XX:SurvivorRatio : New 영역 / Survivor 영역 비율 설정
-XX:NewRatio : Young Gen, Old Gen의 비율 설정
-XX:+DisableExplicitGC : System.gc() 무시 설정
-XX:+CMSPermGenSweepingEnabled : Perm Gen 영역도 GC의 대상이 되도록 설정
-XX:+CMSClassUnloadingEnabled : Class 데이터도 GC의 대상이 되도록 설정
요약
JVM 설정은 전체 메모리의 50%이하로 설정
사용자 환경에 따라 다르지만 최대 26GB이하로 설정하는 것을 권장합니다. 물론 환경에 따라 30GB까지 가능합니다.
소규모 프로젝트 및 개발 환경에서는 리소스를 절약하게 위해 단일 노드로 사용해도 무방합니다. 그러나 프로젝트의 규모가 거대해지고 데이터의 양이 많아지면 그때는 단일 노드로는 불가능한 시점이 오게 되고 Elasticsaerch의 클러스터가 깨지는 위험이 발생할 수 있습니다. 이럴 때 자원을 효율적(효율적이라는 표현은 자원을 적게 쓰는 것이 아닌 역할에 맞게 잘 활용한다는 의미)으로 사용하기 위해서는 노드의 역할을 분배하는 것을 권장하고 있습니다. 노드의 종류는 여러 가지가 있지만 대표적으로 마스터 노드와 데이터 노드를 분리하는 것만으로도 클러스터를 안정적으로 운영할 수 있습니다. 마스터 노드는 클러스터 운영관리 및 노드, 샤드를 관리하는 역할을 수행하고 데이터 노드는 데이터를 저장하고 검색하는 역할을 수행합니다. 마스터와 데이터의 역할을 분리하게 되면 마스터는 온전히 마스터의 역할만 수행하게 되어 마스터 노드에 문제가 발생할 문제가 줄어들게 됩니다. 마스터 노드를 설정할 때는 마스터 선출을 위한 Vorting이 이루어 지게 되므로 홀수개로 설정하는 것을 권장합니다. 마스터 노드를 여러 개로 설정할 경우 실제로 마스터의 역할을 수행하는 것은 1개이며 나머지는 현재 마스터 노드의 문제가 발생할 경우 마스터로 승격되어 마스터 노드의 역할을 수행할 수 있도록 Standby형태로 대기하고 있습니다.
Scale In시 주의사항 (in kubernetes)
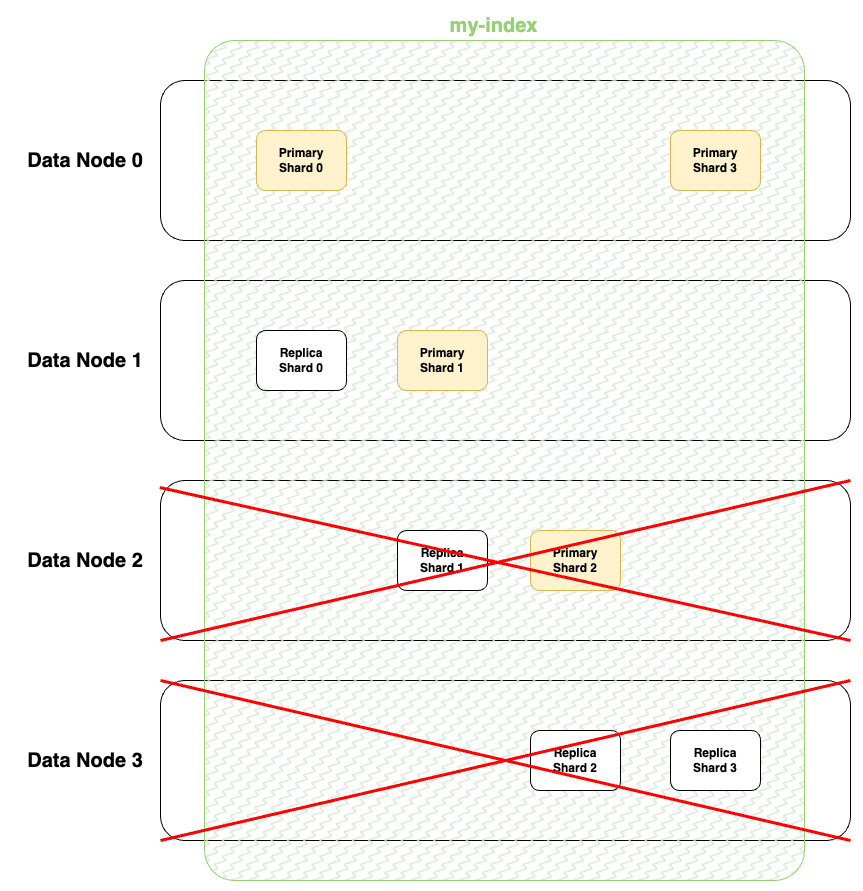
인덱스의 데이터는 샤드로 분할하여 데이터가 저장됩니다. 이때 Replica Shard를 지정하지 않았다면 데이터 노드의 Scale In을 수행할 때 데이터의 손실이 발생할 수 있습니다. 물론 Replica Shard를 구성하더라도 무턱대로 Scale In을 수행하면 데이터의 손실일 발생할 수 있습니다. 아래 그림은 Scale In 수행시 데이터 손실이 발생하는 경우입니다.
그림에서 볼 수 있듯이 Replica Shard가 존재하더라도 Data Node 2번과 3번이 같이 드랍되면 Shard2번의 데이터는 손실되게 됩니다. 그렇기 때문에 Scale In을 수행할 때는 1개씩 줄여가면서 데이터의 복사가 완전히 이루어지면 다음 노드를 줄이는 것을 권장합니다.
Scale Up시 주의사항(in kubernetes)
저 같은 경우 Elasticsearch를 Kubernetes 환경에서 사용하고 있습니다. 만약 마스터 노드가 1개밖에 없는 상황에서 마스터 노드를 스케일업을 수행하게 되면 클러스터가 깨질 수 있습니다. 그 이유는 해당 마스터 노드가 드랍될 때 마스터의 역할을 수행할 수 있는 노드가 없기 때문입니다. 그렇기 때문에 Kubernetes환경에서 마스터 노드가 1개 일 경우 스케일업을 수행할 때는 반듯이 먼저 스케일 아웃을 하여 해당 마스터 노드가 드랍되더라도 마스터의 역할을 대신할 수 있는 노드가 있기 때문에 문제없이 클러스터를 운영할 수 있습니다.
노드는 무조건 많으면 좋을까?
노드의 개수가 많으면 데이터를 분할 저장하고 부하를 나눠 받기 때문에 무조건 좋게 느껴질 수 있습니다. 그러나 각각의 노드들은 서로 통신을 하며 클러스터를 유지하기 때문에 노드가 너무 많게 되면 서로 통신하느라 클러스터의 문제가 발생할 수 있습니다. 그래서 저는 스토리지가 부족하면 스케일아웃을 수행하고 CPU, Memory 리소스가 부족하면 스케일업을 수행하고 있습니다. 무엇이 부족한지 측정하기 위해서는 Elasticsearch Exporter를 설치하여 Prometheus, Grafana를 통하여 측정할 수 있습니다.
Elasticsearch는 파일을 메모리에 매핑하고 해당 Lucene MMapDirectory을 통하여 인덱스 샤드가 저장됩니다. 이러한 동작 과정에서 많은 데이터를 처리하기 위해 어느 정도 크기의 가상 주소 공간이 필요합니다. 그러나 기본적으로 대부분의 운영체제에서는 65,630 만큼의 mmap 개수로 설정되어 있는데 이 수치는 elasticsearch를 운영하는데 매우 작은 양입니다. 그래서 별도로 설정을 하지 않고 Elasticsearch를 실행시키면 bootstrap에 의해 해당 vm.map_map_count의 값이 매우 작다는 Error가 발생하면서 Elasticsearch가 종료합니다. 이러한 문제를 해결하기 위해 vm.max_map_count의 값을 262,144 값으로 수정하여 사용하시면 됩니다.
수정 방법
# 명령어로 변경하면 재부팅 시 유지되지 않는다.
$ sudo sysctl -w vm.max_map_count = 262144
# 파일 수정으로 영구적으로 값 유지 vm.max_map_count 수정
$ vim /etc/sysctl.conf
# max_map_count 값 확인
$ sysctl vm.max_map_count
Kubernetes 환경에서 설치된 Elasticsearch는?
kubernetes 환경에서 helm을 통하여 elasticsearch를 설치하셨다면 해당 설정을 굳이 하실 필요가 없는데요 그 이유는 Elasticsearch StatefulSet의 initcontainer의 "configure-sysctl"이라는 컨테이너가 Elasticsearch가 구동되기 전에 해당 설정을 적용하고 Elasticsearch가 동작하기 때문입니다.
대부분의 운영체제에서는 메모리 관리를 효율적으로 하기 위해서 메모리 스와핑이라는 기술을 사용합니다. 메모리 스와핑은 메모리가 부족하거나 현재 사용되지 않거나 우선순위가 낮은 프로세스의 데이터를 메모리 스와핑을 통하여 디스크에 이동시켜 메모리를 효율적으로 사용하는 방법인데 Elasticsearch에서는 이러한 메모리 스와핑이 치명적인 성능 저하의 원인이 될 수 있습니다.
Elasticsearch는 메모리를 많이 사용하는 특성을 가지고 있는데 메모리 스와핑 작업에 의해 가비지 컬렉션이 비정상적으로 느려지며 노드가 데이터를 디스크로 쓰이고 읽어지는 과정에서 데이터를 처리하는데 응답속도가 매우 느려지고 이러한 문제로 인하여 클러스터와의 연결이 끊어지는 문제가 발생하게 됩니다. 그래서 Elasticsearch 공식 문서에서는 메모리 스와핑을 비활성화하는 것을 권장하고 있습니다.
메모리 스왑핑 비활성
# 명령어로 일시적으로 스와핑 비활성화
$ sudo swapoff -a
# 파일 수정으로 영구적으로 비활성화
$ vi /etc/fstab
# 스왑 상태 확인 명령어
$ free
# 스왑 디렉토리 확인
$ cat /proc/swaps
# 스왑 통계 확인
$ sar -B 2 5
메모리 스와핑을 비활성화하기 때문에 Elasticsearch가 동작하는 노드에 다른 애플리케이션이 같이 동작하는 것은 권장하지 않습니다.
메모리 스와핑 비활성을 할 수 없는 상황이라면?
환경 특성상 메모리 스와핑을 비활성화할 수 없는 상황이라면 최대한 스와핑 주기를 낮춰 발생 빈도를 줄이는 방법이 있습니다.
# 명령어로 설정
$ sudo sysctl vm.swappiness=1
# 설정 확인
$ cat /proc/sys/vm/swappiness
memory_lock 설정
만약에 현제 root 권한이 없어 메모리 스와핑 설정이 불가능한 경우에는 bootstrap.memory_lock 설정을 통하여 메모리 스와핑을 최소화할 수 있습니다. 커널 수준에서 제공되는 함수 중에 mlockall()가 있는데 이 함수는 프로세스의 페이징을 금지하고 모든 메모리가 램에 상주하는 것을 보장해 줍니다. memory_lock을 이용하여 애플리케이션에서 메모리를 강제로 스와핑 하지 못하도록 설정합니다.
memory_lock 설정
# memory_lock 설정하기
$ vi ./elasticsearch.yml
bootstrap.memory_lock: true
# Request를 보내 memory_lock 설정 여부 확인하기
curl -XGET http://localhost:9200/_nodes?filter_path=**.mlockall
Elasticsearch에서는 클러스터의 노드끼리 소켓을 사용해 통신을 하며, 루씬 인덱스에서 데이터를 색인 처리하는데 많은 수의 파일을 사용하고 있습니다. 그렇기 때문에 파일을 열람할 수 있는 크기가 매우 작으면 문제가 될 수 있기 때문에 설정을 통하여 max open file의 수를 지정해 주어야 합니다.
max open file 설정
# 명령어를 통하여 일시적인 적용
$ sudo su
$ ulimit -n 81920
# 파일 수정을 통하여 영구적인 적용
$ vim /etc/security/limits.conf
irterm softnofile 81920
irterm hardnofile 81920
Elasticsearch에서는 기본적으로 각각의 노드에 샤드가 일정 비율로 균등하게 배치되도록 하고 있습니다. 그래도 뜻하지 않게 특정 노드에 샤드가 많이 배치될 수도 있고 어떤 인덱스는 샤드의 크기가 매우 커서 노드의 스토리지 사용량이 불균형이 발생할 수도 있습니다. 이런 경우 Elasticsearch에서 reroute를 이용하여 해당 문제를 해결할 수 있습니다.
샤드 재배치
해당 인덱스의 특정 샤드를 reroute를 이용하여 "elasticsearch-data-1"에서 "elasticsearch-data-3"노드로 이동하도록 하겠습니다.
해당 request를 처리하는데 관여한 노드의 정보와 인덱스 샤드의 대한 정보가 출력되며 disk의 설정 값까지 출력됩니다.
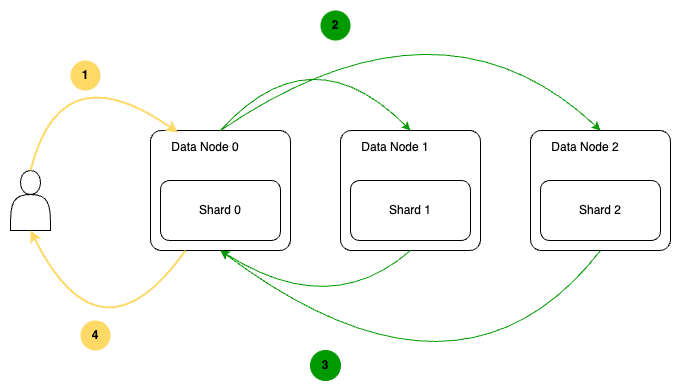
request를 수행하기 전과 수행한 후의 샤드의 배치 모습을 아래와 같이 그림으로 그렸습니다. 여기서 중요한 것은 "Shard 0"의 Primary shard와 Replica shard가 고가용성(HA)을 유지하기 위해서 같은 노드에 존재하게 하면 안 됩니다.
마지막으로
위에서 설명한 것처럼 샤드는 인덱스 별로 크기가 모두 다르기 때문에 스토리지 사용량을 균일하게 분배할 때 용이하게 사용할 수 있을 것 같습니다. 또한 reroute는 샤드의 재배치뿐만 아니라 특정 노드가 드롭되었을 때 샤드를 복구하는 과정에서 해당 샤드를 어디에 배치하는지에 대한 설정도 가능합니다. 자세한 내용은 아래 elasticsearch 공식 문서를 참고해 주세요
Elasticsearch의 Cluster는 물리적으로 나뉜 하나 이상의 노드를 논리적으로 하나의 서버 그룹으로 묶어 관리하는 것입니다. 하나의 노드로 모든 역할을 수행할 수 있도록 설정할 수 있지만 그렇게 설정할 경우 하나의 노드가 모든 부하를 받기 때문에 클러스터가 깨질 수 있는 위험이 있습니다. 물론 개인 테스트 환경 및 개발환경에서는 리소스를 아끼기 위해 이렇게 설정할 수 있지만 상용으로 사용할 경우 Cluster를 구성할 때는 각각의 노드가 역할을 분리하여 한 노드의 문제가 발생하더라도 클러스터를 유지하는데 문제가 없게 클러스터를 구성하는 것이 좋습니다.
각 노드들의 역할
위에서 설명한 것처럼 Elasticsearch에서는 모든 역할을 수행하는 하나의 노드로 클러스터를 구성할 수도 있지만 안정적인 클러스터를 운영하기 위해서 각각의 노드의 역할을 분리하여 관리할 수 있습니다. 뿐만 아니라 규모가 커질 경우 자신에 상황에 맞게 해당 노드에 리소스를 할당하여 리소스를 보다 효율적으로 사용할 수 있습니다. Elasticsearch 노드의 종류와 기능은 다음과 같습니다.
마스터 노드 (Master node)
마스터 노드는 Elasticsearch의 클러스터 전체를 관리하며 각 노드들의 연결 상태 및 인덱스 및 샤드의 상태 등을 관리하는 역할을 수행합니다. 마스터 노드의 개수를 여러 개 설정하여 현재 마스터는 하나만 수행하고 나머지 마스터 노드는 현재 마스터 노드에 문제가 발생하면 마스터로 승격될 수 있도록 스탠바이 형식으로 구성하여 안정적인 클러스터 운영을 할 수 있습니다. 마스터 노드의 개수는 보팅 알로리즘으로 인한 스플릿 브레인 현상이 발생하지 않도록 1개 이상의 홀수개로 생성하는 것을 권장합니다.
데이터 노드 (Data node)
데이터 노드는 이름 그대로 데이터를 처리하는 노드입니다. 데이터를 저장하고 색인처리를 수행하며 저장된 데이터를 검색하는 역할을 수행할 수 있습니다. 데이터 노드를 여러 개 생성하여 데이터를 분산 저장하여 하나의 노드에 부하가 몰리는 것을 방지할 수 있습니다. 데이터 노드는 hot, warm, cold 등으로 여러 개로 분리하여 리소스를 보다 효율적으로 사용할 수 있도록 설정할 수 있습니다.
코디네이팅 노드 (Coordinating Node)
코디네이팅 노드는 요청을 받아서 해당 요청을 처리하는 역할을 수행합니다. 코디네이팅 노드는 별도로 설정하는 것이 아닌 요청을 받은 노드를 코디네이팅 노드라고 합니다. 그렇기 때문에 일반적으로 데이터 노드에서 코디네이팅 역할을 같이 수행하도록 하지만 대규모 클러스터에서는 데이터를 저장하지 않고 요청만 받아서 처리하는 코디네이팅 노드를 별도로 구성하여 요청에 대한 부하를 분리하기도 합니다.
Elasticsearch cluster 구성도
저는 별도로 사용해 본 적은 없지만 그밖에 ingest, ml, client, transform 등 여러 형식의 노드 또한 존재합니다.
index, shard, document
도큐먼트 (Document)
도큐먼트는 Elasticsearch의 가장 작은 데이터 단위를 나타냅니다. 도큐먼트는 JSON 형식으로 표현되며 인덱스로 색인되어 저장됩니다. 데이터가 인덱싱 될 때 자동으로 고유한 도큐먼트 아이디가 생성되어 저장됩니다.
인덱스 (Index)
인덱스는 Elasticsearch의 핵심적인 기능으로 데이터를 그룹화하여 데이터를 저장하고 검색 및 통계를 할 수 있도록 하는 기능을 수행합니다. 인덱스는 고유한 이름을 가지며 하나 이상의 샤드로 구성되어 여러 노드에 분산되어 데이터가 저장됩니다. index는 template을 구성하여 데이터를 보다 효율적으로 관리할 수 있으며 ilm(Index Lifecycle Manager)를 통해 인덱스의 생명주기를 관리할 수 있습니다.
인덱스 구성 방법
Long term retention index : 인덱스의 크기가 크지 않고 변화가 많지 않아 지속적으로 데이터를 읽기 위해 사용하는 방식으로 단일 인덱스로 구성된 방식입니다.
Rolling update : 인덱스를 my-index-2023-09-29, my-ingdex-2023-09-30 등과 같이 날짜별로 구성하여 관리하는 방식입니다. 날짜별로 데이터가 분리되어 저장되었기 때문에 시계열 데이터 및 로그와 같은 데이터인 경우 날짜별로 인덱스를 관리하고 검색하여 보다 효율적으로 사용할 수 있는 방식입니다. 뿐만 아니라 날짜 별로 데이터를 스냅샷을 찍을 수 있으며 복구할 수 있어 데이터를 날짜별로 관리해야 되는 경우 매우 유용한 방식입니다.
Rollover : 인덱스의 크기를 예측하기 어려운 경우 사용하는 방식입니다. 하나의 인덱스가 너무 크면 해당 인덱스의 검색에 많은 부하를 받을 수 있기 때문에 인덱스가 일정 개수의 도큐먼트 또는 일정 크기에 도달했을 경우 인덱스를 분리하여 저장하는 방식입니다. 예시로 my-index-0001, my-index-0002 형식으로 데이터가 저장되며 검색할 때는 모든 같은 형식의 이름의 인덱스를 Alias를 통해 모두 검색합니다.
샤드 (Shard)
인덱스를 구성하는 단위로 인덱스는 하나 이상의 샤드로 구성됩니다. Elasticsearch에서는 각 노드에 부하를 분산하기 위해 샤드를 기반으로 한 인덱스의 데이터가 분산 저장하게 됩니다. 또한 데이터를 검색하는 데 있어 병렬로 데이터를 검색하여 빠른 검색 및 색인이 가능해집니다. 샤드의 수는 인덱스가 생성되고 나서 수정할 수 없어 새롭게 생성되는 인덱스에만 샤드를 설정할 수 있습니다. 또한 샤드는 Primary 샤드와 Replica 샤드로 구분되며 Primary 샤드는 원본 데이터를 저장하고 Replica 샤드에서는 Primary 샤드를 복제하여 고가용성(HA)을 보장해 주는 역할을 수행합니다.
샤드는 Elasticsearch 7 버전부터 기본값으로 인덱스당 1개가 생성되게 되어 있습니다. 그렇기 때문에 인덱스를 생성할 때 샤드의 개수를 지정해야 됩니다. 만약 너무 많은 양의 샤드를 구성할 경우 Master 노드에서 클러스터를 운영하는데 부하를 받기 때문에 샤드의 크기는 하나의 샤드당 30GB 이하의 크기를 가지도록 설정하여 적당한 개수를 가지게 하는 것을 권장합니다. 인덱스당 샤드를 최대 1024개까지 구성할 수 있습니다.
Lucene
Shard는 루씬 인덱스로 구성되며 루씬 인덱스는 여러개의 segment로 구성되어 있습니다. 다수의 세그먼트로 분산되어 있기 때문에 병렬로 데이터를 검색을 수행하며 역색인 형식으로 데이터를 저장하여 검색에 최적화되어 있습니다. IndexWriter를 통하여 새로운 세그먼트가 생성되고 세그먼트의 개수가 늘어나면 주기적으로 각각의 세그먼트를 병합(merge)하여 일정 크기의 세그먼트를 유지하게 됩니다.
세그먼트는 읽기 전용이기 때문에 한번 기록되면 변경이 불가능합니다. 데이터가 변경되면 새로운 세그먼트가 생성되고 변경된 내용이 반영되기 위해서는 Commit이라는 작업을 통해 이루어집니다. 세그먼트가 인덱스 샤드에 구성되는 모습은 다음과 같습니다.
segment
검색 동작 과정
Request를 요청하게 되면 Request를 수신한 노드(코디네이팅 노드)는 해당 인덱스의 샤드를 가지고 있는 데이터 노드에게 검색을 요청하게 됩니다. 그럼 해당 샤드에서 조건에 맞는 데이터를 검색하여 리턴하게 되고 사용자 요청을 수신한 노드에서 결과를 통합하여 사용자에게 전달합니다.
kubernetes 환경에서 elasticsearch를 설치하는 방법을 정리하였습니다. 비록 테스트 환경이지만 실제 운영환경처럼 구성하기 위해 3대의 마스터 노드와 2대의 데이터 노드로 구성하였습니다(현업에서 직접 사용할 경우 보다 더 여유 있는 구성을 추천드립니다) 3대의 마스터 노드 중 실제로 마스터의 역할을 수행하는 것은 1대이며 나머지 2대의 마스터 노드는 현재 마스터 노드의 문제가 발생할 경우 마스터로 승격할 수 있도록 Standby 형식으로 구성하였습니다.
elasticsearch 디렉토리로 이동하여 values 값을 설정합니다. 저의 경우 values.yaml 파일을 직접적으로 수정하는 것보다는 새로운 yaml을 구성하여 values.yaml 파일을 override 하여 사용하는 것을 선호하기 때문에 마스터 노드와 데이터 노드 별로 설정파일을 구성하여 작업하였습니다.
master.yaml 파일 구성
마스터 노드는 3대로 구성되어 있고 클러스터 유지를 위해 CPU는 4 코어, Memory는 16GB로 여유 있게 구성하였습니다. 그리고 Lucene의 메모리 사용을 위해 16GB의 절반인 8GB만 JVM옵션으로 설정을 하였습니다.
Elasticsearch 라이센스 문제로 현재 7.10 버전을 사용하고 있습니다. 그러나 7.10 버전에서는 AWS S3에 저장하는 기능이 기본적으로 제공하고 있지 않습니다. 그래서 7.10 버전을 AWS S3에 스냅샷 저장하는 방법에 대하여 문서를 작성하였습니다. (참고로 8.0 버전 이상에서는 기본적으로 AWS S3 Snapshot을 제공하고 있습니다. 8.0 이상의 버전을 사용하시는 분들은 큰 제목 3번부터 진행하셔도 됩니다.)
1. 현재 나의 환경은?
저의 경우 Elasticsearch를 kubernetes에 설치하여 사용하고 있습니다. 그렇기 때문에 Kubernetes 환경 위주로 설명을 진행하지만 플러그인 설치하는 방법은 비슷하므로 일반적인 VM 방법과 Kubernetes 및 Docker에서 사용하는 방법에 대하여 정리하였습니다.
VM Elasticsearch
Elasticsearch는 공식적으로 제공하지 않는 부분에 있어 Elasticsearch Plugin을 통하여 확장 기능을 설치할 수 있도록 제공하고 있습니다. 이런 기능을 사용하여 Elasticsearch가 설치된 VM으로 접속하여 아래 명령어를 통하여 모든 노드에 AWS S3 Plugin을 설치하여 줍니다.
kubernetes, docker 환경에서는 플러그인을 설치하여 재시작을 하게 되면 해당 파드가 초기화가 되기 때문에 위 방법을 사용하지 않고 Elasticsearch 이미지를 다시 생성하여 사용해야 합니다.
FROM docker.elastic.co/elasticsearch/elasticsearch:7.10.2
RUN bin/elasticsearch-plugin install --batch repository-s3
다음과 같이 Dockerfile을 생성하여 이미지를 빌드하고 빌드된 이미지를 사용합니다.
docker build -t (이미지) (도커파일경로)
2. Helm을 이용하여 Elasticsearch 설치 진행
저는 아래의 ArtifactHub를 통해 Elasticsearch 설치 작업을 진행하였습니다. 해당 문서는 AWS S3 스냅샷에 대한 내용이므로 Helm 사용법에 대해서는 추후 문서를 작성하여 링크를 붙이도록 하겠습니다. values.yaml 파일을 다음과 같이 수정하여 Elasticsearch 설치를 진행합니다. https://artifacthub.io/packages/helm/elastic/elasticsearch
SLM(Snapshot Lifecycle Management) 를 진행하실 분은 해당 부분을 스킵하여도 됩니다. 해당 Request를 통하여 스냅샷 생성이 성공적으로 진행이 되었다면 스냅샷 정보와 스냅샷에 성공한 샤드와 실패한 샤드에 대한 개수를 알려줍니다. 종종 네트워크의 문제로 특정 노드의 샤드가 실패할 수 있는데 이런 경우 다시 시작하여 주시면 됩니다.
위에서 생성한 스냅샷으로 복구하는 방법은 다음과 같습니다. 그러나 여기서 명심해야 되는 것은 이미 같은 이름의 인덱스가 Elasticsearch에 존재하면 안 됩니다. 스냅샷은 특정 시점으로 돌아가는 것이기 때문에 같은 이름의 인덱스가 존재하면 해당 인덱스를 삭제해야 합니다.
curl -X POST "http://localhost:9200/_snapshot/my_repository/backup-2023-06-13-hci5ctcoq9wjfiwiuy2osg/_restore?pretty" -H "Content-Type: application/json" -d '
{
"indices": "*"
}'
# 결과
{"accepted":true}
elasticdump는 Elasticsearch 인덱스와 데이터를 내보내거나 가져오기 위한 도구입니다. elasticdump를 사용하면 Elasticsearch 클러스터의 index, document, template 등을 백업하거나 다른 클러스터로 마이그레이션하는 작업을 수행할 수 있습니다. 본 문서에서 elasticdump의 기본 적인 사용법에 대해서 정리하였습니다.
elasticdump install
$ sudo apt update
$ sudo apt install npm
$ npm install elasticdump -g
$ elasticdump --version
6.103.0
(node:16397) NOTE: We are formalizing our plans to enter AWS SDK for JavaScript (v2) into maintenance mode in 2023.
(생략...)
Elasticsearch Index의 데이터를 파일로 가져오기
Index의 documents데이터를 디렉토리에 파일로 가져올 수 있습니다. 현재 Index에 저장된 데이터는 다음과 같습니다.
Elsticsearch에서 index의 template을 지정하지 않을 경우 인덱스를 생성할 때마다 shard 및 field type을 계속해서 지정을 해줘야 하는 귀찮은 문제가 발생합니다. 저 같은 경우 인덱스를 날짜 별로 생성하는 Rolling 방식을 이용하고 있는데 만약 template이 존재하지 않았다면 매일 00시마다 인덱스를 생성하는 노가다를 하게 될 겁니다.
template를 사용하게 되면 특정 패턴의 인덱스가 생성될때 template으로 지정된 설정이 자동으로 적용되어 인덱스가 생성되기 때문에 shard, refresh, field 타입이 자동으로 적용됩니다.
Field data type 종류
default 타입으로 설정되어 생성됩니다. 문자열인 경우 keyword, text 둘 다 지정되며, 숫자인 경우 long 타입으로 설정됩니다. 기본 값으로 사용하는데 문제가 없다면 그냥 사용해도 되지만 최적화를 하거나 리소스의 자원을 아끼며, 상황에 맞게 Analyzer의 기능을 사용할 때는 반듯이 template을 생성하고 해당 template를 기반으로 인덱스가 생성되어 사용하는 것을 권장합니다.
각각의 필드의 타입에 대해서는 아래 elasticsearch 공식 document를 통하여 확인하여 주시기 바랍니다.
먼저 인덱스 Template를 설정하기 전에 ilm에 대해서 간단하게 알아보겠습니다. ilm이란 Index Lifecycle Management로 인덱스의 생명 주기 및 인덱스 크기를 관리해 주는 기능입니다. 위 설정은 "my-log-policy"라는 ilm을 생성하는 API이며 파라미터의 대한 설명은 다음과 같습니다.
policy.phases.delete.min_age : 인덱스의 생명 주기입니다. 저는 3일로 설정하였습니다.
policy.phases.delete.action : 3일 뒤 수행하는 action입니다. 저는 인덱스가 생성된 지 3일이 지나면 해당 인덱스를 삭제하도록 설정하였습니다.
이번 문서는 인덱스 Template에 대한 설명이기 때문에 ilm policy의 삭제에 대해서만 간단하게 설정하였습니다. ilm의 기능으로는 삭제뿐만 아니라 hot, warm, cold, rollover등과 같은 여러 가지의 기능을 제공하고 있습니다.
Index template 설정하기
"my-log-template"이라는 template를 shard 개수를 4개, 각 샤드의 복제본 1개 그리고 5초마다 한 번씩 refresh를 수행하여 데이터가 검색될 수 있도록 설정을 하며 필드의 타입은 다음과 같이 설정하도록 하였습니다.
인덱스의 template은 인덱스 필드의 데이터 타입을 설정하는 것뿐만 아니라 인덱스의 전체적인 설정을 지정하는 기능을 합니다. 인덱스는 하나 이상의 샤드로 구성되어 있습니다. 샤드는 인덱스의 데이터를 분할되어 여러 노드에 나눠 저장되어 한 노드에 부하가 집중되는 것을 방지하며 replica 샤드를 통하여 고가용성(HA)을 보장하는 기능을 수행합니다. 이러한 설정을 인덱스의 template 설정을 통하여 지정할 수 있습니다. 위 request를 통하여 "my-log-template"라는 template을 설정하고 "my-log-"로 시작되는 모든 인덱스에 해당 설정이 적용됩니다. 파라미터에 대한 설명은 다음과 같습니다.
index_patterns : 해당 templat이 적용되는 인덱스명의 패턴을 입력합니다. 저는 "my-log-"로 시작되는 새롭게 생성되는 인덱스에 template이 적용되도록 설정하였습니다.
settings.index.number_of_shards : 인덱스는 하나 이상의 샤드로 구성되어 있는데 샤드의 개수를 늘려 여러 노드에 분할 저장될 수 있도록 설정할 수 있습니다. 해당 설정은 샤드의 개수를 지정하는 것인데 너무 많은 설정으로 구성하면 Elasticsearch의 Cluster 전체에 악영향을 미칠 수 있기 때문에 적당한 양의 샤드로 구성하는 것을 권장합니다. 저는 웬만하면 Data Node 개수의 배수로 설정하여 여러 Data Node에 골고루 분할할 수 있도록 설정합니다. 한 인덱스에 최대로 설정할 수 있는 샤드의 개수는 1024개입니다.
settings.index.number_of_replicas : 고가용성을 보장하기 위해 복제본 샤드의 개수를 설정합니다. 너무 많은 복제 샤드를 설정하면 데이터 보존의 안정성은 보장되지만 클러스터에 많은 부하가 발생할 수 있습니다. 저는 복제본 샤드를 1개로 구성하여 HA를 보장하지만 클러스터에 부하를 최소한으로 하도록 설정하여 사용합니다.
settings.index.refresh_interval : Elasticsearch는 데이터가 저장되면 바로 검색이 되지 않습니다. 인덱스에 refresh가 되어야지 검색이 가능해집니다. refresh가 1초마다 되면 실시간에 가깝게 검색을 수행할 수 있지만 데이터에 삽입되는 Indexing의 성능이 저하될 수 있습니다. 만약 실시간 검색이 중요하면 1초로 설정하지만 그렇지 않다면 어느 정도 긴 시간을 설정하는 것을 추천합니다. 저 같은 경우 로그 데이터 엄청 많은 양의 데이터가 발생할 수 있기 때문에 데이터가 안정적으로 들어오는 것이 중요하다고 판단하여 5초로 설정하였습니다. ML분야에 개발자 분들은 하루동안 데이터를 모으고 다음날 데이터를 분석할 때는 refresh가 하루에 한 번 또는 한 시간에 한번 수행하는 경우도 있다고 합니다.
settings.index.lifecycle.name : 인덱스의 lifecycle을 지정합니다. 위에서 설정한 ilm을 지정하여 인덱스가 생성되고 3일 뒤에 삭제 하도록 하였습니다.
mappings.properties : 데이터 필드의 타입을 지정합니다. level필드는 keyword타입, timestamp는 date타입, logger는 keyword타입, message는 text타입, action은 keyword타입으로 설정하였습니다. 이 것 이외에 여러 데이터 타입이 있습니다.
mappings.dynamic_templates : dynamic_template은 데이터의 필드 명칭이 명확하지 않을때 사용하는 기능입니다.
mappings.dynamic_templates.message : message dynamic_template은 문자열로 입력된 msg로 시작되는 명칭의 필드가 들어오면 해당 필드의 타입은 text로 지정합니다.
mappings.dynamic_templates.default_strings : 모든 문자열로 들어온 지정되지 않은 필드는 무조건 keyword 타입으로 설정합니다.
mappings.dynamic_templates.default_number : 모든 숫자형식으로 들어온 지정되지 않은 필드는 무조건 integer 타입으로 설정합니다.
Elasticsearch의 template설정은 데이터 삽입 및 검색의 성능에 많은 영향을 미칠 수 있습니다. 자신의 환경 및 상황에 맞게 인덱스를 설정한다면 보다 더 효율적인 클러스터 운영이 가능해지기 때문에 데이터의 형식 및 검색할 때 어떻게 검색할 것인지를 파악하고 template를 반듯이 설정하는 것을 권장합니다.
다운로드하고 압축을 풀면 압축 푼 폴더에 bin/kibana.bat를 실행합니다. 특별한 설정을 하지 않았다면 Elasticsearch는 9200 포트로 설정되고 kibana는 5601 포트로 설정됩니다. 웹 브라우저 주소창에 http://localhost:5601에 접속하여 kibana가 설치되었는지 확인합니다. 그리고 Explore on my own을 선택하면 됩니다.
Kibana와 Elasticsearch 연결 확인하기
Elasticsearch와 kibana가 실행되고 있다면 http://localhost:5601로 접속하여 Dev tools를 선택하여 들어갑니다.
Dev tools로 들어와서 GET / 명령를 실행하여 다음과 같이 출력되었다면 정상적으로 연결이 된 것입니다.