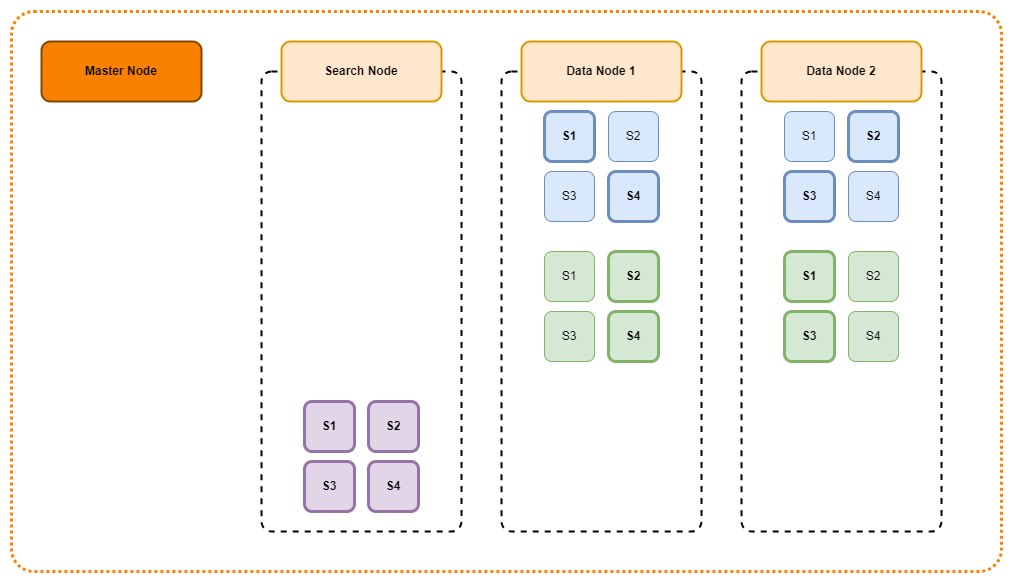
kubernetes 환경에서 elasticsearch를 설치하는 방법을 정리하였습니다. 비록 테스트 환경이지만 실제 운영환경처럼 구성하기 위해 3대의 마스터 노드와 2대의 데이터 노드로 구성하였습니다(현업에서 직접 사용할 경우 보다 더 여유 있는 구성을 추천드립니다) 3대의 마스터 노드 중 실제로 마스터의 역할을 수행하는 것은 1대이며 나머지 2대의 마스터 노드는 현재 마스터 노드의 문제가 발생할 경우 마스터로 승격할 수 있도록 Standby 형식으로 구성하였습니다.

1. Helm chart 다운로드
저는 kubernets 환경에서 elasticsearch를 설치하기 위해 helm을 사용하였습니다. 아래 링크의 helm으로 구성하였습니다.
https://artifacthub.io/packages/helm/elastic/elasticsearch
elasticsearch 8.5.1 · elastic/elastic
Official Elastic helm chart for Elasticsearch
artifacthub.io
helm 명령어를 통하여 repo를 추가하고 다운로드합니다.
# helm repo 추가
$ helm repo add elastic https://helm.elastic.co
# helm 파일 다운로드
$ helm pull elastic/elasticsearch
$ ls -al
drwxr-xr-x@ 6 hsw staff 192 6 25 09:45 .
drwxr-xr-x@ 9 hsw staff 288 6 25 09:44 ..
-rw-r--r--@ 1 hsw staff 28898 6 25 09:45 elasticsearch-8.5.1.tgz
# helm 압축 출기
$ tar -zxvf elasticsearch-8.5.1.tgz
$ ls -al
drwxr-xr-x@ 6 hsw staff 192 6 25 09:45 .
drwxr-xr-x@ 9 hsw staff 288 6 25 09:44 ..
drwxr-xr-x@ 12 hsw staff 384 6 25 10:26 elasticsearch
-rw-r--r--@ 1 hsw staff 28898 6 25 09:45 elasticsearch-8.5.1.tgz
2. values.yaml 수정
elasticsearch 디렉토리로 이동하여 values 값을 설정합니다. 저의 경우 values.yaml 파일을 직접적으로 수정하는 것보다는 새로운 yaml을 구성하여 values.yaml 파일을 override 하여 사용하는 것을 선호하기 때문에 마스터 노드와 데이터 노드 별로 설정파일을 구성하여 작업하였습니다.
master.yaml 파일 구성
마스터 노드는 3대로 구성되어 있고 클러스터 유지를 위해 CPU는 4 코어, Memory는 16GB로 여유 있게 구성하였습니다. 그리고 Lucene의 메모리 사용을 위해 16GB의 절반인 8GB만 JVM옵션으로 설정을 하였습니다.
tolerations, nodeAffinity의 경우 사용자 환경에 맞게 설정하여 사용해 주세요 사용법은 링크를 달아놨습니다.
tolerations : https://kubernetes.io/ko/docs/concepts/scheduling-eviction/taint-and-toleration/
nodeAffinity : https://kubernetes.io/ko/docs/concepts/scheduling-eviction/assign-pod-node/
##################################
# cluster info
createCert: false
clusterName: "elasticsearch"
nodeGroup: "master"
replicas: 3
imageTag: "7.10.2"
roles:
- master
##################################
# nodeAffinity
tolerations:
- key: "develop/elasticsearch-master"
operator: "Exists"
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: develop/group
operator: In
values:
- elasticsearch-master
##################################
# cluster config
# 테스트 환경이라 보안 설정을 끔
esConfig:
elasticsearch.yml: |
xpack.security.enabled: false
# AWS S3 스냅샷 테스트를 위한 설정
esJvmOptions:
jvm.options: |
-Des.allow_insecure_settings=true
##################################
# resources
esJavaOpts: "-Xmx8g -Xms8g"
resources:
requests:
cpu: 4
memory: "16Gi"
limits:
cpu: 4
memory: "16Gi"
volumeClaimTemplate:
resources:
requests:
storage: 10Gi
storageClassName: openebs
##################################
# service
protocol: http
service:
type: NodePort
nodePort: "30090"data.yaml 파일 구성
데이터 노드의 경우 마스터 노드보다 더 많은 요청을 처리하고 데이터 관리를 수행하기 때문에 마스터 노드보다 더 여유 있는 스펙으로 리소스를 구성하였습니다. 데이터 노드 또한 마스터 노드처럼 사용자의 환경에 맞는 값으로 구성해 주세요
##################################
# cluster info
createCert: false
clusterName: "elasticsearch"
nodeGroup: "data"
replicas: 2
imageTag: "7.10.2"
roles:
- data
- ingest
##################################
# nodeAffinity
tolerations:
- key: "develop/elasticsearch-data"
operator: "Exists"
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: develop/group
operator: In
values:
- elasticsearch-data
##################################
# cluster config
# 테스트 환경이라 보안 설정을 끔
esConfig:
elasticsearch.yml: |
xpack.security.enabled: false
# AWS S3 스냅샷 테스트를 위한 설정
esJvmOptions:
jvm.options: |
-Des.allow_insecure_settings=true
##################################
# resources
esJavaOpts: "-Xmx16g -Xms16g"
resources:
requests:
cpu: 8
memory: "32Gi"
limits:
cpu: 8
memory: "32Gi"
volumeClaimTemplate:
resources:
requests:
storage: 200Gi
storageClassName: openebs
##################################
# service
# UI 사용을 위해 NodePort로 설정
protocol: http
service:
type: NodePort
nodePort: "30091"Makefile 구성
저는 지속적으로 지웠다 설치했다는 반복 하는데 편리하기 위해 Makefile을 구성하였습니다.
PREFIX := es
TIMEOUT := 1200s
NAMESPACE := elasticsearch
install:
helm upgrade --wait --timeout=$(TIMEOUT) --install -n $(NAMESPACE) --create-namespace --values override-master.yaml $(PREFIX)-master .
helm upgrade --wait --timeout=$(TIMEOUT) --install -n $(NAMESPACE) --create-namespace --values override-data.yaml $(PREFIX)-data .
purge:
helm del $(PREFIX)-master -n $(NAMESPACE)
helm del $(PREFIX)-data -n $(NAMESPACE)
3. 설치 진행
Makefile을 이용하여 설치를 진행합니다.
# elasticsearch 설치
$ make install
설치 작업이 완료 되면 Elasticsearch는 다음과 같이 구성됩니다.
pod/elasticsearch-data-0 1/1 Running 0 1d
pod/elasticsearch-data-1 1/1 Running 0 1d
pod/elasticsearch-master-0 1/1 Running 0 1d
pod/elasticsearch-master-1 1/1 Running 0 1d
pod/elasticsearch-master-2 1/1 Running 0 1d
service/elasticsearch-data NodePort 10.233.47.200 <none> 9200:30091/TCP,9300:31095/TCP 1d
service/elasticsearch-data-headless ClusterIP None <none> 9200/TCP,9300/TCP 1d
service/elasticsearch-master NodePort 10.233.56.28 <none> 9200:30090/TCP,9300:32277/TCP 1d
service/elasticsearch-master-headless ClusterIP None <none> 9200/TCP,9300/TCP 1d
statefulset.apps/elasticsearch-data 2/2 1d
statefulset.apps/elasticsearch-master 3/3 1d
4. Elasticsearch 삭제
테스트가 끝나고 elasticsearch를 지우기 위해서는 다음과 같이 진행하면 됩니다.
# Elasticsearch 제거
$ make purge
'Elasticsearch > Elasticsearch 설정' 카테고리의 다른 글
| Elasticsearch reroute 샤드를 다른 노드로 이동시키기 (0) | 2023.10.03 |
|---|---|
| Elasticsearch 클러스터 구조 (0) | 2023.09.30 |
| Elasticsearch 7.10 버전 AWS S3 Snapshot 생성하기(in Kubernetes) (0) | 2023.07.04 |
| Elasticdump 사용해보기 (0) | 2023.07.03 |
| Elasticsearch의 Index template 설정하기 (0) | 2021.08.24 |