
JVM 설정
elasticsearch JVM이라고 검색을 해보면 많은 글들이 JVM은 전체 메모리에 50%로 설정하라고 설명하는 곳이 많습니다. 그렇지만 단순히 50%라고만 하기에는 사용자의 환경이 다르기 때문에 설명이 부족합니다. elasticsearch 공식 문서에 따르면 전체 메모리의 50% 이하로 설정하는 것을 권장하고 있으며, 환경에 따라 다르지만 대중적으로 26GB 이하로 설정해야 된다고 설명을 하고 있지만 사용자의 환경에 따라 30GB까지도 설정을 할 수 있다고 합니다. 그 이유는 Zero base comporessed OOP 때문인데요 Compressed OOP는 아래에서 다루도록 하겠습니다. 그리고 JVM 설정에 유의해야 되는 것은 전체 메모리의 50% 이하를 JVM에 줬다면 나머지 메모리는 시스템과 Lucene이 사용하게 됩니다. 그렇기 때문에 통계 및 분석이 많은 쿼리를 자주 사용한다면 JVM에 메모리를 높게 주고(50%에 가깝게) 검색만 주로 하는 쿼리를 자주 사용한다면 JVM메모리를 보다 적게 주어 Lucene이 더 많은 메모리를 사용할 수 있게 하는 것이 좋습니다.
Compressed OOP
포인터의 공간 낭비를 줄이고 좀 더 빠른 연산을 위해 포인터를 압축해서 표현하는 메모리 최적화 기법 중 하나입니다. 이 기법의 원리는 포인터가 메모리 주소를 가리키는게 아닌 Object Offset을 가리키도록 변형해서 동작시키는 것입니다. 만약 8비트 포인터를 사용한다면 256바이트의 물리적인 주소를 표현하는게 아니라 256개의 객체를 가리킬 수 있게 되는 것입니다. 만약 JVM의 크기가 32GB를 넘어가게 된다면 포인터 구조가 Compressed OOP가 아닌 일반 OOP 방식으로 전환되어 Compressed OOP의 이점을 살릴 수가 없습니다. 그러므로 메모리의 여유가 있다면 차라리 노드를 더 늘려 주는 것이 더 현명한 선택이 될 것 같습니다.
Compressed OOP 메모리 주소
- 32비트 OOP : 2의 32승 까지의 주소를 가리킬 수 있다. 4GB
- 64비트 OOP : 2의 64승 까지의 주소를 가리킬 수 있다. 18EB
- 32비트 Compressed OOP : 2의 32승 오브젝트를 가리킬 수 있습니다.
- 메모리 공간으로는 2의 32승 곱하기 8만큼 표현이 가능합니다.
Zero base Compressed OOP 확인
Zero base Compressed OOP는 JVM의 힙 메모리가 0번지부터 시작하게 하는 설정이다. JVM의 크기가 32GB로 설정하여 Zero base Compressed OOP가 깨진 것과 30GB 이하로 설정하여 Zero base Compressed OOP가 활성화된 것의 차이를 확인해 보겠습니다.
JVM 32GB
$ java -Xmx32768m -XX:+PrintFlagsFinal -XX:+UnlockDiagnosticVMOptions -XX:+PrintComressedOopsMode 2>/dev/null | grep Compressed | grep Oops
bool PrintCompressedOopsMode = true
bool UseCompressedOops = false
JVM 30GB
$ java -Xmx30720m -XX:+PrintFlagsFinal -XX:+UnlockDiagnosticVMOptions -XX:+PrintComressedOopsMode 2>/dev/null | grep Compressed | grep Oops
heep address : 0x0000000...
bool PrintCompressedOopsMode = true
bool UseCompressedOops = true
JVM 여러가지 옵션
Elasticsearch 공식 문서에 따르면 Xms, Xmx의 값은 동일해야 하며 전체 메모리의 50% 이하로 설정하며 root jvm.options 파일을 수정하지 않는 것을 권장합니다. 저는 Xms, Xmx만 수정하고 나머지는 그냥 이런 것들이 있다는 것만 알고 넘어갔습니다.
- -Xms : 기본 heep 사이즈 (기본값 : 64MB)
- -Xmx : 최대 heep 사이즈 (기본값 : 256MB)
- -XX:PermSize : 기본 Perm 사이즈
- -XX:MaxPermSize : 최대 Perm 사이즈
- -XX:NewSize : 최소 New 영역 사이즈
- -XX:MaxNewSize : 최대 New 영역 사이즈
- -XX:SurvivorRatio : New 영역 / Survivor 영역 비율 설정
- -XX:NewRatio : Young Gen, Old Gen의 비율 설정
- -XX:+DisableExplicitGC : System.gc() 무시 설정
- -XX:+CMSPermGenSweepingEnabled : Perm Gen 영역도 GC의 대상이 되도록 설정
- -XX:+CMSClassUnloadingEnabled : Class 데이터도 GC의 대상이 되도록 설정
요약
- JVM 설정은 전체 메모리의 50%이하로 설정
- 사용자 환경에 따라 다르지만 최대 26GB이하로 설정하는 것을 권장합니다. 물론 환경에 따라 30GB까지 가능합니다.
- 26GB 또는 30GB가 넘으면 Zero base compressed OOP가 깨짐
- 통계 및 분석을 많이 사용하면 JVM을 50%에 가깝게 설정
참고
Advanced configuration | Elasticsearch Guide [8.10] | Elastic
This functionality is in technical preview and may be changed or removed in a future release. Elastic will apply best effort to fix any issues, but features in technical preview are not subject to the support SLA of official GA features.
www.elastic.co
노드 역할 분리 및 노드 개수
소규모 프로젝트 및 개발 환경에서는 리소스를 절약하게 위해 단일 노드로 사용해도 무방합니다. 그러나 프로젝트의 규모가 거대해지고 데이터의 양이 많아지면 그때는 단일 노드로는 불가능한 시점이 오게 되고 Elasticsaerch의 클러스터가 깨지는 위험이 발생할 수 있습니다. 이럴 때 자원을 효율적(효율적이라는 표현은 자원을 적게 쓰는 것이 아닌 역할에 맞게 잘 활용한다는 의미)으로 사용하기 위해서는 노드의 역할을 분배하는 것을 권장하고 있습니다. 노드의 종류는 여러 가지가 있지만 대표적으로 마스터 노드와 데이터 노드를 분리하는 것만으로도 클러스터를 안정적으로 운영할 수 있습니다. 마스터 노드는 클러스터 운영관리 및 노드, 샤드를 관리하는 역할을 수행하고 데이터 노드는 데이터를 저장하고 검색하는 역할을 수행합니다. 마스터와 데이터의 역할을 분리하게 되면 마스터는 온전히 마스터의 역할만 수행하게 되어 마스터 노드에 문제가 발생할 문제가 줄어들게 됩니다. 마스터 노드를 설정할 때는 마스터 선출을 위한 Vorting이 이루어 지게 되므로 홀수개로 설정하는 것을 권장합니다. 마스터 노드를 여러 개로 설정할 경우 실제로 마스터의 역할을 수행하는 것은 1개이며 나머지는 현재 마스터 노드의 문제가 발생할 경우 마스터로 승격되어 마스터 노드의 역할을 수행할 수 있도록 Standby형태로 대기하고 있습니다.
Scale In시 주의사항 (in kubernetes)
인덱스의 데이터는 샤드로 분할하여 데이터가 저장됩니다. 이때 Replica Shard를 지정하지 않았다면 데이터 노드의 Scale In을 수행할 때 데이터의 손실이 발생할 수 있습니다. 물론 Replica Shard를 구성하더라도 무턱대로 Scale In을 수행하면 데이터의 손실일 발생할 수 있습니다. 아래 그림은 Scale In 수행시 데이터 손실이 발생하는 경우입니다.
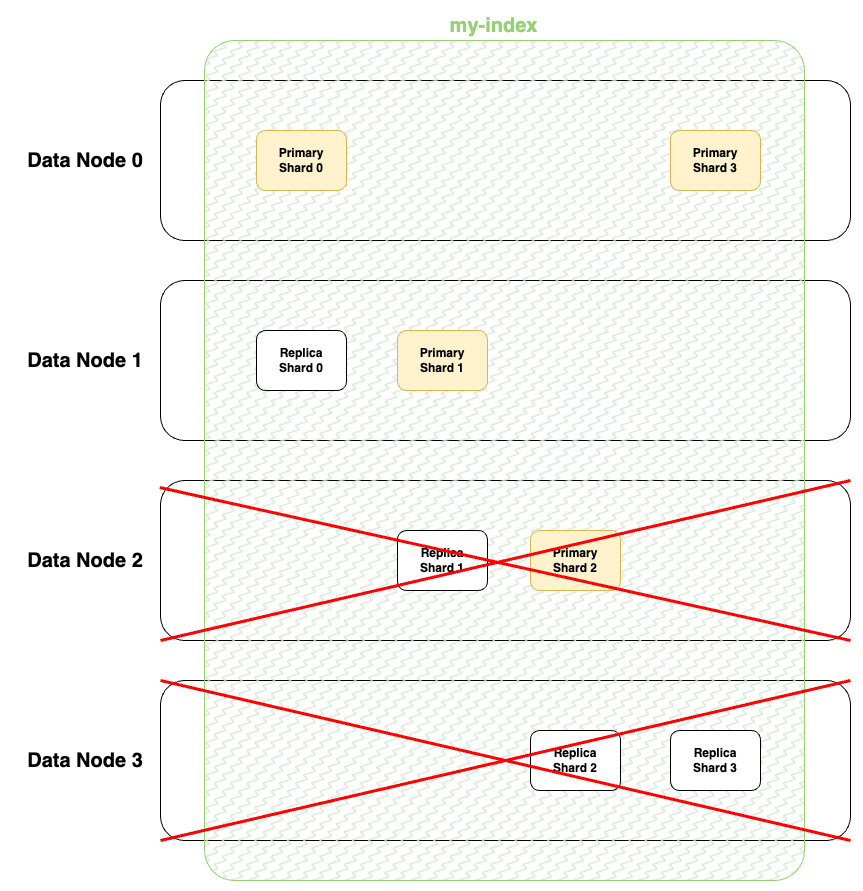
그림에서 볼 수 있듯이 Replica Shard가 존재하더라도 Data Node 2번과 3번이 같이 드랍되면 Shard2번의 데이터는 손실되게 됩니다. 그렇기 때문에 Scale In을 수행할 때는 1개씩 줄여가면서 데이터의 복사가 완전히 이루어지면 다음 노드를 줄이는 것을 권장합니다.
Scale Up시 주의사항 (in kubernetes)
저 같은 경우 Elasticsearch를 Kubernetes 환경에서 사용하고 있습니다. 만약 마스터 노드가 1개밖에 없는 상황에서 마스터 노드를 스케일업을 수행하게 되면 클러스터가 깨질 수 있습니다. 그 이유는 해당 마스터 노드가 드랍될 때 마스터의 역할을 수행할 수 있는 노드가 없기 때문입니다. 그렇기 때문에 Kubernetes환경에서 마스터 노드가 1개 일 경우 스케일업을 수행할 때는 반듯이 먼저 스케일 아웃을 하여 해당 마스터 노드가 드랍되더라도 마스터의 역할을 대신할 수 있는 노드가 있기 때문에 문제없이 클러스터를 운영할 수 있습니다.
노드는 무조건 많으면 좋을까?
노드의 개수가 많으면 데이터를 분할 저장하고 부하를 나눠 받기 때문에 무조건 좋게 느껴질 수 있습니다. 그러나 각각의 노드들은 서로 통신을 하며 클러스터를 유지하기 때문에 노드가 너무 많게 되면 서로 통신하느라 클러스터의 문제가 발생할 수 있습니다. 그래서 저는 스토리지가 부족하면 스케일아웃을 수행하고 CPU, Memory 리소스가 부족하면 스케일업을 수행하고 있습니다. 무엇이 부족한지 측정하기 위해서는 Elasticsearch Exporter를 설치하여 Prometheus, Grafana를 통하여 측정할 수 있습니다.
'Elasticsearch' 카테고리의 다른 글
| Elasticsearch Ingest pipeline enrich processor (0) | 2023.10.18 |
|---|---|
| Elasticsearch 최적화 #3] ilm policy로 data phases 설정 (0) | 2023.10.14 |
| Elasticsearch 최적화 #1] 시스템 설정 (0) | 2023.10.03 |
| Elasticsearch reroute 샤드를 다른 노드로 이동시키기 (0) | 2023.10.03 |
| Elasticsearch copy_to로 여러 필드의 데이터를 하나로 검색 (1) | 2023.10.01 |